AI面接
Download
フォーカスモード
フォントサイズ
シーン紹介
AI面接は、人工知能技術と高品質なRTC通信を活用してオンライン自動面接を実現する新しいソリューションです。従来の面接プロセスでは、面接官の人数、スケジュール調整、主観的評価などの制約により、企業は大規模採用や人材選考において効率の低さ、コスト高、体験の悪さといった課題に直面しがちでした。Conversational AI能力を活用することで、AI面接は企業と求職者双方に24時間利用可能で標準化された効率的なオンライン面接体験を提供します。AI面接官は大規模言語モデル(LLM)を基盤としており、応募者と自然な対話を行い、リアルタイムで質問や追問をすることで総合的な能力を評価し、面接内容を自動的に記録・テキストデータ化して後続の評価をサポートします。
Tencent RTCは基盤技術として、AI面接シーンに安定した高品質で低遅延の音声・映像通信機能を提供します。そのクロスプラットフォームかつグローバルな相互接続性の利点により、面接者はiOS、Android、Windows、Mac、Web、WeChat/QQミニプログラムなど任意の端末を安心して利用でき、いつでもどこでもAI面接に参加できます。早期選考から深堀り質問まで、RTC Engineは常に明確でスムーズなコミュニケーションを保証し、ユーザー体験はネイティブアプリに匹敵します。
企業開発者向けに、RTC Engineは豊富なシーンベースのUIコンポーネントと低い参入障壁の開発接続機能を提供し、わずか数行のコードで迅速に統合し、運用テストを開始できます。企業が自社Appまたは公式アカウント、ミニプログラムにAI面接入り口を導入したい場合でも、容易に実現できます。
実現ソリューション
完全なAI面接シーンは通常、Real-Time Communication(RTC)、Conversational AI、大規模言語モデル(LLM)、Text To Speech(TTS)、面接管理バックエンドなどの主要モジュールで構成されます。以下に、各モジュールのAI面接シーンにおける機能と特徴を示します。
機能モジュール | AI面接シーンアプリケーション |
RTC | RTC Engineを基盤に、高品質で低遅延の音声・映像接続を提供し、720P/1080P/2Kの高精細画質と48kHzの高音質をサポートします。ネットワーク環境に関わらず、スムーズなインタラクションを保証し、実際の面接シーンをシミュレートすることが可能です。 |
Conversational AI | Tencent Conversational AIソリューションは、顧客が複数のAI大規模モデルサービスを柔軟に導入し、AIとユーザー間のRTCインタラクションを実現し、ビジネスシーンに適したConversational AI能力を構築します。Tencent Real-Time Communication(Tencent RTC)のグローバルな低遅延伝送を基盤に、対話効果は自然でリアル、接続は容易で即座に利用可能です。 |
LLM | 候補者の音声内容と文脈をインテリジェントに理解し、応答の要点を正確に抽出し、動的に後続の面接質問を生成することで、個性的で構造化された面接プロセスを実現します。LLM技術はまた、異なる職種のアルゴリズムに基づいて自動的に評価基準を調整し、評価の公平性と正確性を向上させます。 |
TTS | サードパーティのTTSに対応し、複数の言語と音声スタイルの出力をサポートします。AI面接官はTTS技術により異なるトーンや性格を表現し、最大限に本物の面接官をシミュレートすることで、候補者の体験を向上させます。 |
Chat | Chatを通じて重要な業務シグナリングのパススルーを完了します。 |
面接管理バックエンド | 問題バンクと面接設計、自動採点、データストレージ、視覚的分析、面接スケジュール管理などの機能を含みます。 |
ソリューション・アーキテクチャ
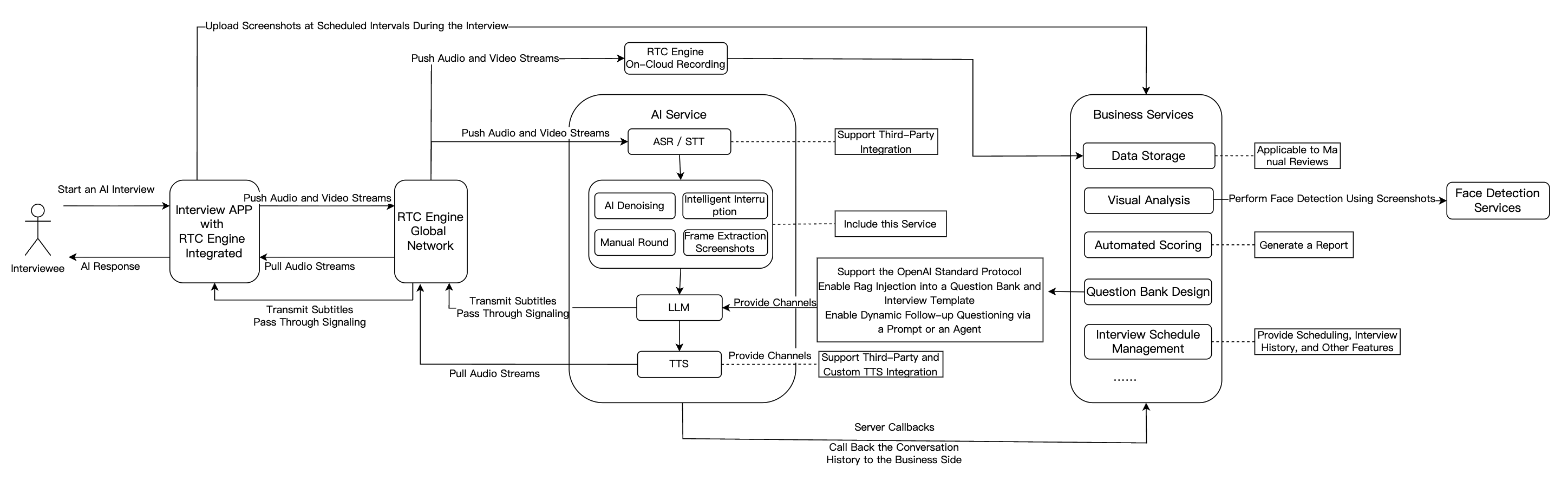
以下では、AI面接導入の主なプロセスについて紹介します。
前提条件
LLMの準備
Conversational AIは、OpenAI標準プロトコルに準拠する任意のLLMモデルをサポートし、Tencent Cloud Agent Development Platform (ADP)、Dify、CozeなどのLLMアプリケーション開発プラットフォームもサポートしています。具体的にサポートされているプラットフォームについては、LLMConfig設定説明をご参照ください。
TTSの準備
Tencent Cloud TTSの使用:
TTS音声合成機能を使用するには、アプリケーションのTTSサービスの開通が必要です。
APPIDはアカウント情報から取得できます。
SecretIdとSecretKeyはAPIキー管理から取得できます。SecretKeyはキー作成時にのみ確認可能ですので、即座に保存してください。
音色リストから調整可能な音色を取得できます。
サードパーティまたはカスタムTTSの使用:現在サポートされているTTSはテキスト音声変換設定(TTSConfig)です。
RTC Engineの準備
注意:
対話型AIサービスの開通をご参照ください。
導入手順
業務フロー図
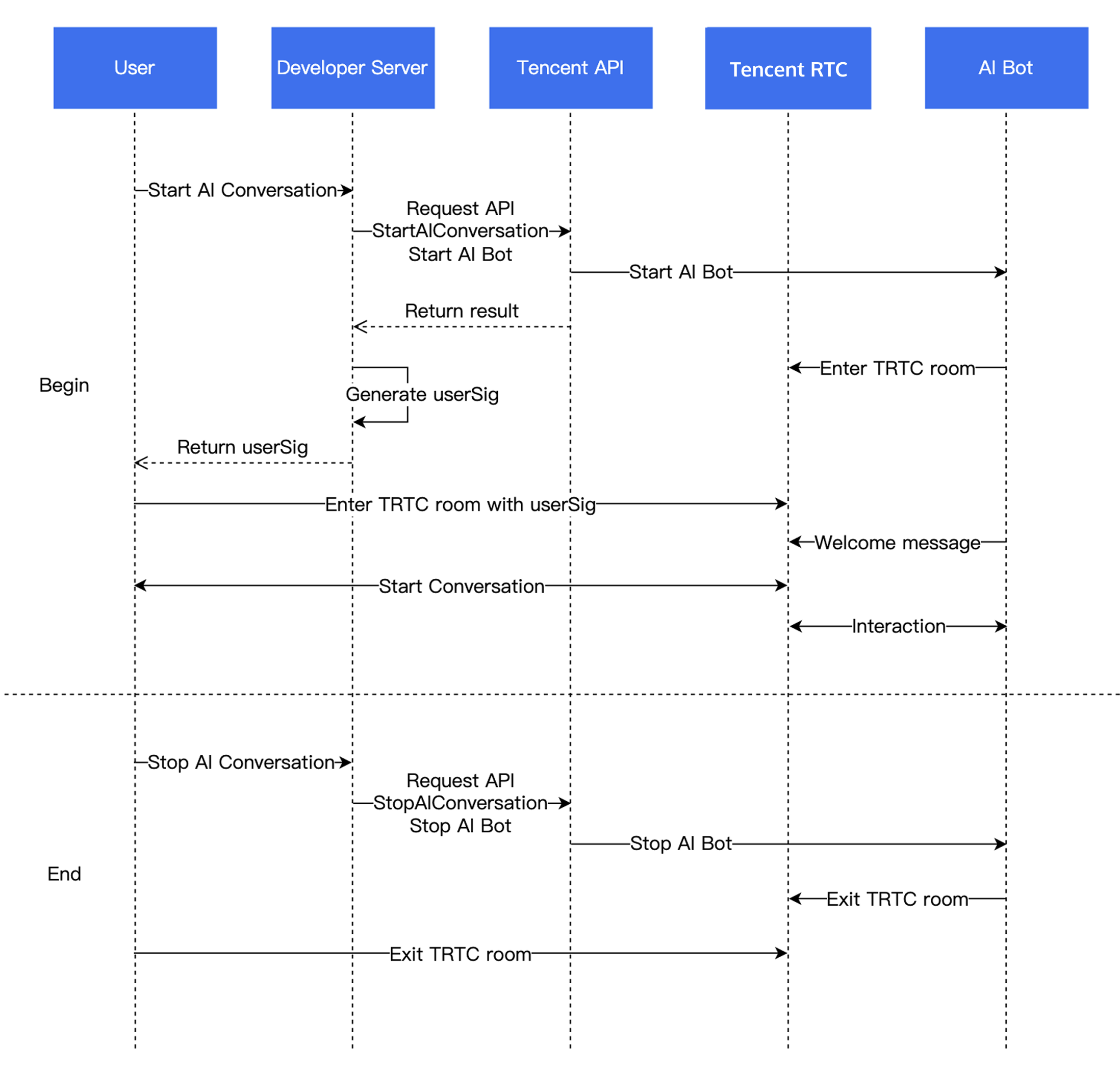
ステップ1:RTC Engine SDKをプロジェクトにインポートし、RTC Engineルームに入室します
ステップ2:オーディオストリームを公開
startLocalAudioを呼び出してマイク収集を開始できます。このインターフェースでは、qualityパラメータを使用して収集モードを指定する必要があります。このパラメータの名前はqualityですが、品質が高いほど良いというわけではなく、異なるビジネスシーンに最適なパラメータ選択があります(このパラメータのより正確な意味はsceneです)。
AI対話シーンではSPEECHモードの使用をお勧めします。このモードでは、SDKのオーディオモジュールが音声信号の抽出に注力し、周囲の環境ノイズを最大限にフィルタリングします。また、このモードのオーディオデータは、劣悪なネットワーク品質に対する耐性も向上します。そのため、このモードは「ビデオ通話」や「オンライン会議」など、音声コミュニケーションを重視するシーンに特に適しています。
// マイク収集を開始し、現在のシーンを音声モード(高ノイズ抑制能力、強弱ネットワーク耐性)に設定しますmCloud.startLocalAudio(TRTCCloudDef.TRTC_AUDIO_QUALITY_SPEECH );
self.trtcCloud = [TRTCCloud sharedInstance];// マイク収集を開始し、現在のシーンを音声モード(高ノイズ抑制能力、強弱ネットワーク耐性)に設定します[self.trtcCloud startLocalAudio:TRTCAudioQualitySpeech];
// マイク収集を開始し、現在のシーンを音声モード(高ノイズ抑制能力、強弱ネットワーク耐性)に設定しますtrtcCloud.startLocalAudio(TRTCAudioQuality.speech);
trtc.startLocalAudio()メソッドを使用してマイクを起動し、ルームに公開します。
await trtc.startLocalAudio();
// マイク収集を開始し、現在のシーンを音声モードに設定します// 高いノイズ抑制能力、強弱ネットワーク耐性を持ちますITRTCCloud* trtcCloud = CRTCWindowsApp::GetInstance()->trtc_cloud_;trtcCloud->startLocalAudio(TRTCAudioQualitySpeech);
// マイク収集を開始し、現在のシーンを音声モードに設定します// 高いノイズ抑制能力、強弱ネットワーク耐性を持ちますAppDelegate *appDelegate = (AppDelegate *)[[NSApplication sharedApplication] delegate];[appDelegate.trtcCloud startLocalAudio:TRTCAudioQualitySpeech];
ステップ3:AI対話を開始
AI対話を開始:StartAIConversation
業務バックエンドからAI対話タスク開始インターフェースを呼び出して、Conversational AIを開始します。呼び出しが成功すると、AIボットがRTC Engineルームに入ります。前提条件のLLMとTTS関連情報を
LLMConfigとTTSConfigに入力します。以下はOpenAI標準プロトコルのLLMモデルを例に、LLMConfigの設定方法を説明します。
設定説明
名称 | タイプ | 必須かどうか | 説明 |
LLMType | String | はい | 大規模モデルタイプは、 OpenAI APIプロトコルに準拠する大規模モデルであれば、すべてopenaiと記入してください。 |
Model | String | はい | 具体的なモデル名、例えば gpt-4o、deepseek-chat。 |
APIKey | String | はい | 大規模モデルの APIKey。 |
APIUrl | String | はい | 大規模モデルの APIUrl。 |
Streaming | Boolean | いいえ | ストリーミングかどうか、デフォルトは falseで、trueを入力することをお勧めします。 |
SystemPrompt | String | いいえ | システムプロンプト。 |
Timeout | Float | いいえ | タイムアウト時間、範囲は[1~50]、デフォルトは3秒(単位:秒)。 |
History | Integer | いいえ | LLMのコンテキストラウンド数を設定。デフォルト値:0(コンテキスト管理を提供しません)、最大値:50(最近50ラウンドのコンテキスト管理を提供)。 |
MaxTokens | Integer | いいえ | 出力テキストの最大 token 制限。 |
Temperature | Float | いいえ | サンプリング温度。 |
TopP | Float | いいえ | サンプリングの選択範囲で、出力 token の多様性を制御。 |
UserMessages | Object[] | いいえ | ユーザープロンプト。 |
MetaInfo | Object | いいえ | カスタムパラメータは、リクエストの body 内に置かれ、大規模モデルに透過転送します。 |
設定例
"LLMConfig": {"LLMType": "openai","Model": "gpt-4o","APIKey": "api-key","APIUrl": "https://api.openai.com/v1/chat/completions","Streaming": true,"SystemPrompt": "あなたは個人アシスタントです","Timeout": 3.0,"History": 5,"MetaInfo": {},"MaxTokens": 4096,"Temperature": 0.8,"TopP": 0.8,"UserMessages": [{"Role": "user","Content": "content"},{"Role": "assistant","Content": "content"}]}
以下にTencent TTSを例として、TTSConfigの設定方法を説明します。
{"TTSType": "tencent", // String TTSタイプ, 現在"tencent"と"minixmax"をサポート、その他のベンダーはサポート予定"AppId": あなたのアプリID, // Integer 必須"SecretId": "あなたのシークレットID", // String 必須"SecretKey": "あなたのシークレットKey", // String 必須"VoiceType": 101001, // Integer 必須、音色ID。標準音色と高品質音色が含まれ、高品質音色はよりリアルで、価格も標準音色と異なります。音声合成の料金概要をご参照ください。完全な音色IDリストは音声合成音色リストをご参照ください。"Speed": 1.25, // Integer 必須でない、話速、範囲:[-2,6]、それぞれ異なる話速に対応: -2: 0.6倍 -1: 0.8倍 0: 1.0倍(デフォルト) 1: 1.2倍 2: 1.5倍 6: 2.5倍 より細かい話速が必要な場合は、小数点以下2桁まで指定可能、例:0.5/1.25/2.81など。パラメータ値と実際の話速の変換については、話速変換をご参照ください"Volume": 5, // Integer 必須でない、音量レベル。範囲:[0,10]、それぞれ11段階の音量に対応。デフォルト値は0で、通常音量を表します。"PrimaryLanguage": 1, // Integer オプション 主要言語 1-中国語(デフォルト) 2-英語 3-日本語"FastVoiceType": "xxxx" // String オプションパラメータ、高速音声複製のパラメータ"EmotionCategory":"angry",// String 必須でない、合成音声の感情を制御し、多感情音色のみ使用可能。値: neutral(中性)、sad(悲しい)..."EmotionIntensity":150 //Integer 必須でない、合成音声の感情強度を制御し、範囲は[50,200]で、デフォルトは100。EmotionCategoryが空でない場合のみ有効。}
現在サポートされている
STTConfig、LLMConfig と TTSConfig の設定説明:注意:
RoomIdはクライアント側で入室するRoomIdと一致している必要があり、部屋番号のタイプ(数字ルーム番号、文字列ルーム番号)も同じでなければなりません(即ち、ボットとユーザーは同じルームにいる必要があります)。TargetUserIdはクライアント側で入室時に使用するUserIdと一致している必要があります。LLMConfigとTTSConfigはどちらもJSON文字列であり、Conversational AIを正常に開始するには、正しく設定する必要があります。ステップ4:対話を開始
この時点で、ユーザーはAIカスタマーサービスと正常に対話できます。
ステップ5:AI対話を停止し、RTC Engineルームを退出します
1. サーバー側でAI対話タスクを停止します。業務バックエンドからAI対話停止インターフェースを呼び出し、この対話タスクを停止します。
2. クライアント側でRTC Engineルームを退出する際は、ルーム退出を参照することをお勧めします。
高度な機能
遠距離人声抑制
AI面接では、AIがユーザー側の他の人の声をユーザーの発言として認識し、返信する場合があります。このような状況をできるだけ避けるために、遠距離人声抑制の能力を使用する必要があります。AI対話タスク開始インターフェースを呼び出す際に、
STTConfig.VadLevelを2または3に設定すると、優れた遠距離人声抑制能力が得られます。対話遅延最適化
Conversational AIにおいて、AIの応答遅延は主にLLM、TTSの先頭パケット処理時間、およびASRのVadSilenceTime、RTC Engineチャネルの遅延によって構成されます。
RTC Engineは独自開発の多重最適アドレス検出アルゴリズムを採用し、ネットワーク全体のスケジューリング能力を備えており、エンドツーエンドの平均遅延は300ms未満です。LLMやTTSの先頭パケット遅延と比較して、RTC Engineの遅延は非常に小さいため、開発者は通常その遅延を気にする必要はありません。
ASRの処理時間は基本的にVadSilenceTimeによって決まります。高すぎると対話の遅延が増加し、低すぎるとASRの文切れ間隔が短くなり、ユーザーが話す際に少しでも間を空けると、完全な発話として認識され、LLMにリクエストが送信されます。
LLMとTTSの先頭パケット処理時間はAI応答遅延に最も影響を与える部分であり、開発者はクライアントコールバックとサーバーコールバックを通じてLLMとTTSの先頭パケット処理時間のコールバックを取得できます。
指標名の説明
ステータスコード | 説明 |
asr_latency | ASR遅延。注:この指標には、AI対話開始時にVadSilenceTimeで設定された時間が含まれます。 |
llm_network_latency | LLMリクエストのネットワーク処理時間。 |
llm_first_token | LLMの先頭 token 処理時間、この指標にはネットワーク処理時間が含まれます。 |
tts_network_latency | TTSリクエストのネットワーク処理時間。 |
tts_first_frame_latency | TTS先頭フレーム処理時間、この指標にはネットワーク処理時間が含まれます。 |
tts_discontinuity | TTS未連続の回数は、TTSストリーミングリクエストの再生完了後、次のリクエスト結果がまだ返されていないことを示し、通常はTTSの遅延が比較的高いことが原因です。 |
interruption | このラウンドの対話が中断されたことを示します。 |
最も重要なデータは、llm_first_token(LLMの先頭パケット処理時間)とtts_first_frame_latency(TTSの先頭フレーム処理時間)です。
llm_first_token
LLMの先頭パケット処理時間は2秒以内に抑えることを推奨し、低ければ低いほど良いです。音声対話シーンでは、LLMにストリーミング返信を使用することをお勧めします(LLMConfigの
Streamingをtrueに設定する必要があります)。これにより遅延を大幅に低減できます。DeepSeek-R1などの思考型モデルは選択しないことをお勧めします。この種のLLMは遅延が大きすぎるため、音声対話に適用できません。対話遅延に特に敏感な場合は、パラメータがより小さいモデルを選択できます。多くのモデルでは先頭パケット処理時間を500ms前後に抑えることが可能です。さらに、追加のAgentやワークフロープラットフォームを接続すると、先頭パケット処理時間が高くなる可能性があります。 LLM + Prompt を単独で使用した場合の処理時間は一般的に低くなります。
tts_first_frame_latency
ほとんどのTTSの先頭フレーム処理時間は一般的に500ms~1000ms程度です。処理時間が特に長い場合は、音色やTTSプロバイダーを変更することで、対話遅延体験を最適化できます。
AI対話字幕とAI状態の受信
リアルタイム字幕の受信
メッセージ形式:
{"type": 10000, // 10000はリアルタイム字幕の配信を示します"sender": "user_a", // 発言者のuserid"receiver": [], // 受信者useridリスト、このメッセージは実際にはルーム内でブロードキャストされます"payload": {"text":"", // 音声認識されたテキスト"start_time":"00:00:01", // この文の開始時間"end_time":"00:00:02", // この文の終了時間"roundid": "xxxxx", // 一連の対話を一意に識別します"end": true // trueの場合、これは完全な文であることを示します}}
ボットの状態を受信
メッセージ形式:
{"type": 10001, // ボットの状態"sender": "user_a", // 送信者userid、ここはボットのidです"receiver": [], // 受信者useridリスト、このメッセージは実際にはルーム内でブロードキャストされます"payload": {"roundid": "xxx", // 一連の対話を一意に識別します"timestamp": 123,"state": 1, // 1 聴取中 2 思考中 3 発言中 4 中断された 5 発言終了}}
サンプルコード
@Overridepublic void onRecvCustomCmdMsg(String userId, int cmdID, int seq, byte[] message) {String data = new String(message, StandardCharsets.UTF_8);try {JSONObject jsonData = new JSONObject(data);Log.i(TAG, String.format("receive custom msg from %s cmdId: %d seq: %d data: %s", userId, cmdID, seq, data));} catch (JSONException e) {Log.e(TAG, "onRecvCustomCmdMsg err");throw new RuntimeException(e);}}
func onRecvCustomCmdMsgUserId(_ userId: String, cmdID: Int, seq: UInt32, message: Data) {if cmdID == 1 {do {if let jsonObject = try JSONSerialization.jsonObject(with: message, options: []) as? [String: Any] {print("Dictionary: \\(jsonObject)")} else {print("The data is not a dictionary.")}} catch {print("Error parsing JSON: \\(error)")}}}
trtcClient.on(TRTC.EVENT.CUSTOM_MESSAGE, (event) => {let data = new TextDecoder().decode(event.data);let jsonData = JSON.parse(data);console.log(`receive custom msg from ${event.userId} cmdId: ${event.cmdId} seq: ${event.seq} data: ${data}`);if (jsonData.type == 10000 && jsonData.payload.end == false) {// 字幕中間状態} else if (jsonData.type == 10000 && jsonData.payload.end == true) {// 一言で完了}});
void onRecvCustomCmdMsg(const char* userId, int cmdID, int seq,const uint8_t* message, uint32_t msgLen) {std::string data;if (message != nullptr && msgLen > 0) {data.assign(reinterpret_cast<const char*>(message), msgLen);}if (cmdID == 1) {try {auto j = nlohmann::json::parse(data);std::cout << "Dictionary: " << j.dump() << std::endl;} catch (const std::exception& e) {std::cerr << "Error parsing JSON: " << e.what() << std::endl;}return;}}
void onRecvCustomCmdMsg(String userId, int cmdID, int seq, String message) {if (cmdID == 1) {try {final decoded = json.decode(message);if (decoded is Map<String, dynamic>) {print('Dictionary: $decoded');} else {print('The data is not a dictionary. Raw: $decoded');}} catch (e) {print('Error parsing JSON: $e');}return;}}
説明:
当社は、さらに多くのAI対話クライアントのコールバックがあります。詳細は以下をご参照ください。AI対話状態コールバック、AI対話字幕コールバック、AI対話指標コールバック、AI対話エラーコールバック。
代理 LLM
AI対話サービスは標準的なOpenAI仕様をサポートしており、開発者が自社の業務でカスタマイズされたLLMを実装できるようになります。開発者は自社の業務バックエンドでOpenAI APIと互換性のある大規模モデルインターフェースを実装し、コンテキストロジックやRAGをカプセル化した大規模モデルリクエストをサードパーティの大規模モデルに送信できます。実装フローは以下の通りです。

このフローチャートは、カスタムコンテキスト管理の基本的な手順を示しています。開発者は自身の具体的なニーズに応じてこのプロセスを調整および最適化できます。
サンプルコード
import timefrom fastapi import FastAPI, HTTPExceptionfrom fastapi.middleware.cors import CORSMiddlewarefrom pydantic import BaseModelfrom typing import List, Optionalfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIapp = FastAPI(debug=True)# CORS ミドルウェアを追加app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],)class Message(BaseModel):role: strcontent: strclass ChatRequest(BaseModel):model: strmessages: List[Message]temperature: Optional[float] = 0.7class ChatResponse(BaseModel):id: strobject: strcreated: intmodel: strchoices: List[dict]usage: dict@app.post("/v1/chat/completions")async def chat_completions(request: ChatRequest):try:# リクエストメッセージを LangChain メッセージ形式に変換langchain_messages = []for msg in request.messages:if msg.role == "system":langchain_messages.append(SystemMessage(content=msg.content))elif msg.role == "user":langchain_messages.append(HumanMessage(content=msg.content))# add more historys# LangChain の ChatOpenAI モデルを使用chat = ChatOpenAI(temperature=request.temperature,model_name=request.model)response = chat(langchain_messages)print(response)# OpenAI API 形式に準拠したレスポンスを構築return ChatResponse(id="chatcmpl-" + "".join([str(ord(c))for c in response.content[:8]]),object="chat.completion",created=int(time.time()),model=request.model,choices=[{"index": 0,"message": {"role": "assistant","content": response.content},"finish_reason": "stop"}],usage={"prompt_tokens": -1, # LangChain はこの情報を提供しないため、プレースホルダ値を使用します"completion_tokens": -1,"total_tokens": -1})except Exception as e:raise HTTPException(status_code=500, detail=str(e))if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)
LLMを通じてカスタムシグナルを透過転送
大規模モデルがTTSに参加しないコンテンツを返す必要がある場合、大規模モデルの返すコンテンツにカスタムフィールド
metainfoを追加できます。AIサービスがmetainfoを検出すると、カスタムメッセージを通じてクライアントSDKに発信し、metainfoのパススルーを完了します。大規模モデル側の送信方法:大規模モデルがストリーミングで
chat.completion.chunkオブジェクトを返す際に、同時にmeta.infoのchunkを返します。{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{"content":"Hello"},"logprobs":null,"finish_reason":null}]}// 以下のカスタムメッセージを追加{"id":"chatcmpl-123","type":"meta.info","created":1694268190,"metainfo": {}}{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-xxxx", "system_fingerprint": "fp_xxxx", "choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
クライアント側での受信方法:AIサービスが
metainfoを検出した後、RTC Engineのカスタムメッセージを通じて配信します。クライアント側ではSDKコールバックのonRecvCustomCmdMsgインターフェースを通じて受信できます。{"type": 10002, // カスタムメッセージ"sender": "user_a", // 送信者userid、ここはボットのidです"receiver": [], // 受信者useridリスト、このメッセージは実際にはルーム内でブロードキャストされます、"roundid": "xxxxxx","payload": {} // metainfo}
Chat を通じて重要なシグナリングを透過転送
業務サーバー側ではクライアントに重要な業務シグナルを透過転送する必要がある場合、Chat SDKを使用して透過転送することをより推奨します。これにより、AIボットが中断されたために
metainfoシグナルが失われる問題を回避できます。サーバー側でのメッセージ送信:
クライアント側でのメッセージ受信:
AI面接官の「話への割り込み」を防きます
手動ラウンドモードを使用
AI対話インターフェースを起動し、
AgentConfig.TurnDetectionModeパラメータを1に設定することで、手動ラウンドモードを有効にできます。この場合、クライアント側では字幕メッセージを受信後、新しい対話をトリガーするためにチャットシグナルを手動で送信するかどうかを独自に決定します。パラメータ説明
パラメータ | タイプ | 説明 |
TurnDetectionMode | Integer | 新しい対話のトリガー方法を制御し、デフォルトは0です。 0は、サーバー側の音声認識で完全な一文を検出した後、自動的に新しい対話ラウンドをトリガーすることを示します。 1は、クライアント側では字幕メッセージを受信後、新しい対話をトリガーするためにチャットシグナルを手動で送信するかどうかを独自に決定することを示します。 サンプル値:0 |
チャットシグナル
{"type": 20000, // 側でカスタムテキストメッセージを送信"sender": "user_a", // 送信者userid、サーバー側ではこのuseridが有効かどうかをチェックします"receiver": ["user_bot"], // 受信者のuseridリスト、ボットのuseridのみ記入してください。サーバー側ではこのuseridが有効かどうかをチェックします"payload": {"id": "uuid", // メッセージidであり、uuidを使用可能、問題の調査に使用"message": "xxx", // メッセージ内容"timestamp": 123 // タイムスタンプ、問題の調査に使用}}
サンプルコード
public void sendMessage() {try {int cmdID = 0x2;long time = System.currentTimeMillis();String timeStamp = String.valueOf(time/1000);JSONObject payLoadContent = new JSONObject();payLoadContent.put("timestamp", timeStamp);payLoadContent.put("message", message);payLoadContent.put("id", String.valueOf(GenerateTestUserSig.SDKAPPID) + "_" + mRoomId);String[] receivers = new String[]{robotUserId};JSONObject interruptContent = new JSONObject();interruptContent.put("type", 20000);interruptContent.put("sender", mUserId);interruptContent.put("receiver", new JSONArray(receivers));interruptContent.put("payload", payLoadContent);String interruptString = interruptContent.toString();byte[] data = interruptString.getBytes("UTF-8");Log.i(TAG, "sendInterruptCode :" + interruptString);mTRTCCloud.sendCustomCmdMsg(cmdID, data, true, true);} catch (UnsupportedEncodingException e) {e.printStackTrace();} catch (JSONException e) {throw new RuntimeException(e);}}
@objc func sendMessage() {let cmdId = 0x2let timestamp = Int(Date().timeIntervalSince1970 * 1000)let payload = ["id": userId + "_\\(roomId)" + "_\\(timestamp)", // メッセージidであり、uuidを使用可能、問題の調査に使用"timestamp": timestamp, // タイムスタンプ、問題の調査に使用"message": "xxx" // メッセージ内容] as [String : Any]let dict = ["type": 20001,"sender": userId,"receiver": [botId],"payload": payload] as [String : Any]do {let jsonData = try JSONSerialization.data(withJSONObject: dict, options: [])self.trtcCloud.sendCustomCmdMsg(cmdId, data: jsonData, reliable: true, ordered: true)} catch {print("Error serializing dictionary to JSON: \\(error)")}}
const message = {"type": 20000,"sender": "user_a","receiver": ["user_bot"],"payload": {"id": "uuid","timestamp": 123,"message": "xxx", // メッセージ内容}};trtc.sendCustomMessage({cmdId: 2,data: new TextEncoder().encode(JSON.stringify(message)).buffer});
注意:
中断遅延の最適化
対話中にAIの発話を中断する遅延が高いと感じる場合、AI対話インターフェース起動内の
AgentConfig.InterruptSpeechDurationとSTTConfig.VadSilenceTimeパラメータを低く設定することで、中断遅延を減らすことができます。誤った中断の確率を下げるために、遠距離人声抑制機能を同時に有効にすることをお勧めします。パラメータ説明
パラメータ | タイプ | 説明 |
AgentConfig.InterruptSpeechDuration | Integer | InterruptModeが0の場合に使用され、単位はミリ秒で、デフォルトは500msです。サーバー側でInterruptSpeechDurationミリ秒継続する人声を検出すると、中断を行うことを示します。 サンプル値:500 |
STTConfig.VadSilenceTime | Integer | 音声認識 vad の時間であり、範囲は240~2000で、デフォルトは1000、単位はmsです。より小さい値にすると音声認識の文切れが速くなります。 サンプル値:500 |
サーバーコールバック
AI対話サーバーコールバックをご参照ください。
注意:
コールバックアドレスはRTC Engineコンソールで設定され、Conversational AIコールバックです。
RTC Engine のルームとメディアコールバックと組み合わせて使用でき、機能を充実させることができます。
クラウドレコーディング
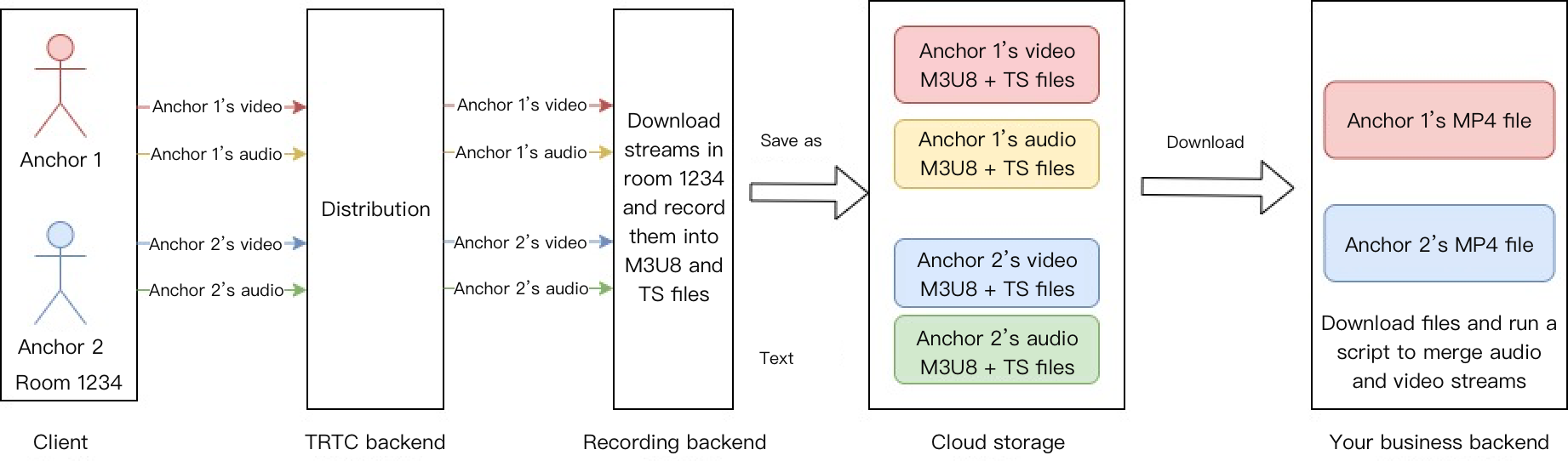
RTC Engineの最新アップグレードしたクラウドレコーディングは、RTC Engine内部のリアルタイム・レコーディング・クラスターを使用してオーディオ・ビデオを録画し、より完全で統一されたレコーディング体験を提供します。
シングルストリーム・レコーディング:RTC Engineのクラウドレコーディング機能を使用して、ルーム内の各ユーザーのオーディオストリームを独立したファイルとしてレコーディングできます。
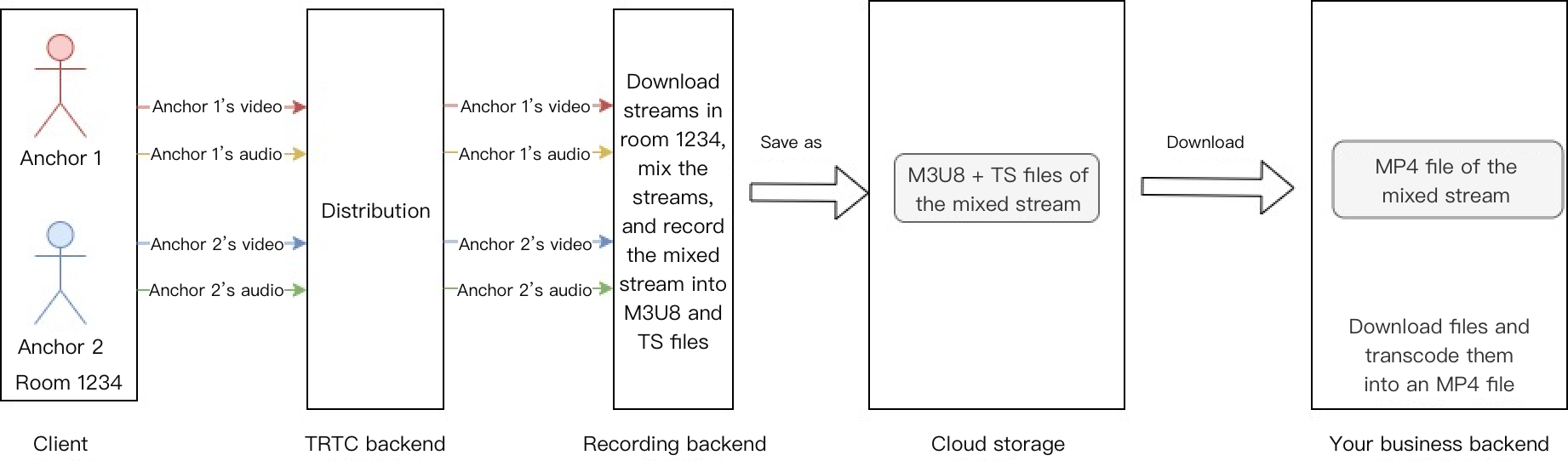
ミックスストリーム・レコーディング:同じルームのオーディオ・メディア・ストリームを1つのファイルにミックスしてレコーディングします。
説明:
よくある質問
なぜボットが話さなかったのですか?
1. クライアント側でマイク収集を有効にし、オーディオストリームを公開しているかどうかを確認してください。
2. RTC Engineのカスタムメッセージ受信機能を通じて、リアルタイム字幕やAIステータスなどのデータを受信できるかどうかを確認します。受信できない場合は、StartAIConversationインターフェースを呼び出す際の
RoomIdがクライアント側での入室時のRoomIdと一致しているか、またルーム番号のタイプ(数字ルーム番号、文字列ルーム番号)も同じである(即ち、ボットとユーザーが同じルームにいる必要がある)ことを確認してください。さらに、TargetUserIdがクライアント側での入室時に使用したUserIdと一致しているかも確認してください。3. 自分の発話の字幕は受信できるが、ボットの返信字幕が受信できない場合は、LLM関連の設定を確認することをお勧めします。
4. ボットの返信字幕は受信できるが、ボットの音声が聞こえない場合は、TTS関連の設定を確認することをお勧めします。
サービスカテゴリ | エラーコード | エラー説明 |
ASR | 30100 | リクエストがタイムアウトしました |
| 30102 | 内部エラー |
LLM | 30200 | LLMリクエストがタイムアウトしました |
| 30201 | LLMリクエストがレート制限されました |
| 30202 | LLMサービスが失敗を返しました |
TTS | 30300 | TTSリクエストがタイムアウトしました |
| 30301 | TTSリクエストがレート制限されました |
| 30302 | TTSサービスが失敗を返しました |
大規模モデル Timeout エラー
LLM Timeoutエラーが発生した場合、例えば
llm error Timeout on reading data from socketというメッセージが表示された場合、通常はLLMリクエストがタイムアウトしたことを意味します。 LLMConfig の Timeout パラメータを大きく設定することができます(デフォルトは3秒)。また、LLMの先頭パケット処理時間が3秒を超える場合、比較的に高い対話遅延がAI対話の体験に影響を与えます。特別な要件がない場合は、LLMの先頭パケット処理時間を最適化することをお勧めします。詳細は対話遅延の最適化をご参照ください。Tencent TTSエラー
Tencent TTSエラーが発生した場合(例えば、以下のエラーなど):
TencentTTS chunk error {'Response': {'RequestId': 'xxxxxx', 'Error': {'Code': 'AuthorizationFailed', 'Message': "Please check http header 'Authorization' field or request parameter"}}}
以下の点から調査できます:
1. アプリのTTSサービスが開通されているか確認してください。
2. APPID、SecretId、SecretKeyが正しく入力されているか確認してください。
3. 無料の TTS リソースパッケージを取得しているか確認してください。
4. 入力した音色IDが無料リソースパッケージに含まれているか確認してください。
ユーザーが単一の文字で回答した場合、なぜLLMにリクエストしないのですか?
ユーザーが「はい」、「いい」などの単一の文字で回答した場合、LLMにリクエストしなければ、AI対話インターフェース起動の
AgentConfig.FilterOneWordパラメータがfalse(デフォルトはtrue)に設定されているかどうかを確認してください。パラメータ | タイプ | 説明 |
FilterOneWord | Boolean | ユーザーが一言しか話していない文をフィルタリングするかどうか、trueはフィルタリング、falseはフィルタリングしない、デフォルト値はtrue サンプル値:true |
異常エラー処理
UserSig 関連。
列挙 | 値 | 説明 |
ERR_TRTC_INVALID_USER_SIG | -3320 | 入室パラメータ UserSig が正しくありません。 TRTCParams.userSig が空でないか確認してください。 |
ERR_TRTC_USER_SIG_CHECK_FAILED | -100018 | UserSig の検証に失敗しました。パラメータ TRTCParams.userSig が正しく入力されているか、または有効期限が切れていないか確認してください。 |
入退室関連。
入室に失敗した場合は、まず入室パラメータが正しいか確認してください。また、入室・退室インターフェースは必ずペアで呼び出す必要があり、入室に失敗した場合でも退室インターフェースを呼び出す必要があります。
列挙 | 値 | 説明 |
ERR_TRTC_CONNECT_SERVER_TIMEOUT | -3308 | 入室リクエストがタイムアウトしました。ネットワーク接続が切断されているか、VPNが有効になっているか確認してください。4Gに切り替えてテストすることもできます。 |
ERR_TRTC_INVALID_SDK_APPID | -3317 | 入室パラメータ SDKAppId が正しくありません。 TRTCParams.sdkAppId が空でないか確認してください。 |
ERR_TRTC_INVALID_ROOM_ID | -3318 | 入室パラメータ roomId が正しくありません。 TRTCParams.roomId または TRTCParams.strRoomId が空でないか確認してください。roomId と strRoomId は混在して使用できませんのでご注意ください。 |
ERR_TRTC_INVALID_USER_ID | -3319 | 入室パラメータ UserID が正しくありません。 TRTCParams.userId が空でないか確認してください。 |
ERR_TRTC_ENTER_ROOM_REFUSED | -3340 | 入室リクエストが拒否されました。 enterRoom を連続して呼び出して同じIDのルームに入ろうとしていないか確認してください。 |
デバイス関連。
デバイス関連のエラーを監視し、関連するエラーが発生した場合にユーザーにUIで通知することができます。
列挙 | 値 | 説明 |
ERR_MIC_START_FAIL | -1302 | マイクの起動に失敗しました。例:WindowsまたはMacデバイスでは、マイクの設定プログラム(ドライバー)に異常がある場合があります。デバイスを無効化して再有効化する、またはマシンを再起動する、または設定プログラムを更新してください。 |
ERR_SPEAKER_START_FAIL | -1321 | スピーカーの起動に失敗しました。例:WindowsまたはMacデバイスではスピーカーの設定プログラム(ドライバー)に異常がある場合があります。デバイスを無効化して再有効化する、またはマシンを再起動する、または設定プログラムを更新してください。 |
ERR_MIC_OCCUPY | -1319 | マイクが使用中です。例えば、モバイルデバイスが通話中の場合、マイク起動に失敗します。 |
ソリューション関連製品
システム階層 | 製品名 | シーン用途 |
アクセス層 | 低遅延で高品質なオーディオ・ビデオのリアルタイムインタラクションソリューションを提供し、オーディオ・ビデオ通話シーンの基盤機能です。 | |
アクセス層 | 重要な業務シグナリングのパススルーを完了します。 | |
クラウドサービス | AIとユーザー間のRTCインタラクションを実現し、ビジネスシーンに合ったConversational AI能力を構築します。 | |
クラウドサービス | 身元確認と不正防止機能を提供します。 | |
大規模モデル | インテリジェントカスタマーサービスの頭脳として、 LLM+RAG、Workflow、Multi-agent など、さまざまなインテリジェントエージェント開発フレームワークを提供します。 | |
データストレージ | オーディオ録音ファイル、オーディオスライスファイルのストレージサービスを提供します。 |
フィードバック