データ最適化をオンにする
ダウンロード
フォーカスモード
フォントサイズ
ビッグデータシナリオでは、頻繁な断片書き込みにより大量の小さなファイルが生成され、これがパフォーマンスを大幅に低下させる可能性があります。データレイクコンピューティング(DLC)は、豊富な生産実践経験に基づき、大規模データ量におけるニアリアルタイムシナリオに対応可能な、効率的でシンプルかつ柔軟なデータ最適化機能を提供します。
説明:
1. Upsertシナリオでは大量の小さなファイルとスナップショットが生成されるため、書き込み前にデータ最適化を設定する必要があります。書き込み後に有効化すると、過去に蓄積された大量の小ファイルを処理するために多大なリソースを消費する可能性があるためです。
2. ユーザーがFlink/Oceans Upsertを使用して書き込む場合、FlinkのCheckPointを5分以上に設定することをお勧めします。これにより、Flinkの書き込みとデータマージの書き込みが競合してマージが失敗し、Deletesファイルが蓄積するのを防ぐことができます。
3. 現在、データ最適化機能はDLCネイティブテーブル(Iceberg)のみをサポートしています。
4. データ最適化タスクの初回実行は、既存のデータ量と選択したエンジンリソース仕様によっては時間がかかる場合があります。
5. データ最適化エンジンとビジネスエンジンは分離することをお勧めします。これにより、データ最適化作業とビジネス作業が互いにリソースを占有し、ビジネス作業が阻害されるのを防ぐことができます。
DLCコンソールでデータ最適化を設定します
DLCデータ最適化ポリシーは、データカタログ、データベース、およびデータテーブルに設定できます。データベースとデータテーブルはデフォルトで上位レベルのデータ最適化ポリシーを継承しますが、ユーザーは特定のデータベースやテーブルに対して個別にデータ最適化ポリシーを設定することもできます。データ最適化を設定する際、ユーザーはデータ最適化タスクを実行するためのエンジンを選択する必要があります。現在データエンジンをお持ちでない場合は、専用データエンジンの購入を参考に購入してください。DLCデータガバナンスはSparkエンジンをサポートしています。
説明:
1. データ最適化ポリシーは、接続タイプがDataLakeCatalogのデータカタログ、データベース、およびデータテーブルに対してのみ適用できます。
2. ユーザーがSuper SQL Sparkジョブエンジンをデータ最適化リソースとして選択した場合、DLCはそのエンジン上で1〜2つのデータ最適化作業を作成します。
3. データ最適化タスクエンジンには、適切に弾力性を有効にすることをお勧めします。
データカタログ設定手順
データカタログに対してデータ最適化戦略を設定する場合、データカタログ編集機能を通じて設定できます。
1. DLC コンソールのメタデータ管理 モジュールに進み、接続タイプが DataLakeCatalog のデータカタログを選択して設定します。
2. データ最適化をクリックすると、確認後、データ最適化戦略が自動的にこのデータカタログに適用されます。
データベース設定手順
特定のデータベースに対して個別にデータ最適化戦略を設定する場合、DLCのデータベース編集機能を使用して、データベースごとにデータ最適化機能を設定できます。
1. DLC コンソールのメタデータ管理 モジュールに進み、データベースリストに入ります。
2. データベースページを開き、データ最適化設定をクリックすると、確認後、データ最適化戦略が自動的にこのデータベースに適用されます。
データテーブル設定手順
特定のデータテーブルに対して個別にデータ最適化戦略を設定する場合、DLCのデータテーブル編集機能を使用して、データテーブルごとにデータ最適化機能を設定できます。
1. DLC コンソールのメタデータ管理 モジュールに進み、データベースリストでデータベースを選択してクリックし、データテーブルリストページに入り、ネイティブテーブルを作成をクリックします。
2. ネイティブテーブル作成ページを開き、対応する最適化リソースを設定すると、確認後、データ最適化戦略が自動的にこのデータテーブルに適用されます。
3. 作成済みのテーブルに対して、データ最適化設定をクリックし、既存のデータテーブルのデータ最適化戦略を編集できます。
説明:
1. データテーブルの作成時または編集時、デフォルトではデータ最適化戦略が上位レベルのデータテーブルのデータ最適化戦略を継承します。データ最適化戦略をカスタマイズする場合は、カスタム構成を選択し、データ最適化リソースと戦略を設定する必要があります。
2. 削除機能にはリスクがあります。ライフサイクルとテーブル有効期限機能は、現在テーブルレベルでの設定のみサポートしています。
3. テーブル有効期限機能によって削除されたテーブルデータは、デフォルトでごみ箱に入ります。ごみ箱が事前に有効になっていない場合、テーブル有効期限機能がトリガーされると自動的にごみ箱が有効になり、デフォルトではごみ箱データの保持期間が7日に設定されます(管理者はごみ箱の保持期間を延長するように変更できます)。
注意:
お客様がライフサイクルとテーブル有効期限機能の両方を設定した場合、システムはタスクのトリガー順序に従って戦略を実行して削除します。設定には十分ご注意ください。
属性フィールドによるデータ最適化の設定
説明:
データベースとデータテーブルのデータ最適化設定は、属性フィールドを通じてのみサポートされています。
上記のビジュアル方式によるデータ最適化設定に加えて、ALTER TABLE/DATABASEを使用して手動でデータベースとテーブルのフィールド属性を指定して設定することもできます。SQLのサンプルは以下の通りです:
// for table govern policyALTER TABLE`DataLakeCatalog`.`wd_db`.`wd_tb`SETTBLPROPERTIES ('smart-optimizer.inherit' = 'none','smart-optimizer.written.enable' = 'enable')// for database govern policyALTER DATABASE`DataLakeCatalog`.`wd_db`SETDBPROPERTIES ('smart-optimizer.inherit' = 'none','smart-optimizer.written.enable' = 'enable')
データ最適化の属性値はすべてALTER文で変更でき、属性値の定義は以下の通りです:
属性値 | 意味 | デフォルト値 | 値の説明 |
smart-optimizer.inherit | 上位ポリシーを継承しますか | default | none:継承しない デフォルト:継承 |
smart-optimizer.written.enable | 書き込み最適化をオンにしますか | disable | disable:無効 enable:オン |
smart-optimizer.written.advance.compact-enable | (オプション)書き込み最適化の詳細パラメータ:小ファイルマージをオンにしますか | enable | disable:無効 enable:オン |
smart-optimizer.written.advance.delete-enable | (オプション)書き込み最適化の詳細パラメータ:データクリーンアップをオンにしますか | enable | disable:無効 enable:オン |
smart-optimizer.written.advance.min-input-files | (オプション)最小入力ファイル数のマージ | 5 | あるテーブルまたはパーティションのファイル数が最小ファイル数を超えた場合、プラットフォームは自動的にチェックし、ファイル最適化マージを開始します。ファイル最適化マージは分析クエリのパフォーマンスを効果的に向上させます。最小ファイル数の値が大きいほどリソース負荷が高くなり、最小ファイル数の値が小さいほど実行が柔軟になり、タスクがより頻繁になります。推奨値は5です。 |
smart-optimizer.written.advance.target-file-size-bytes | (オプション)マージターゲットサイズ | 134217728 (128 MB) | ファイル最適化マージ時、可能な限りファイルをターゲットサイズにマージします。推奨値は128Mです。 |
smart-optimizer.written.advance.retain-last | (オプション)スナップショットの有効期限(単位:日) | 5 | スナップショットの存在時間がこの値を超えると、プラットフォームはそのスナップショットを期限切れとしてマークします。スナップショットの有効期限が長いほど、スナップショットのクリーンアップが遅くなり、ストレージスペースの使用量が増えます。 |
smart-optimizer.written.advance.before-days | (オプション)期限切れスナップショットの保持数 | 2 | 保持数を超えた期限切れスナップショットはクリーンアップされます。保持する期限切れスナップショットの数が多いほど、ストレージスペースの使用量が増えます。推奨値は5です。 |
smart-optimizer.written.advance.expired-snapshots-interval-min | (オプション)スナップショットの有効期限実行サイクル | 600(10 hour) | プラットフォームは定期的にスナップショットをスキャンし、期限切れスナップショットを処理します。実行サイクルが短いほど、スナップショットの期限切れ処理がより敏感になりますが、より多くのリソースを消費する可能性があります。 |
smart-optimizer.written.advance.cow-compact-enable | (オプション)COWテーブル(V1テーブルまたはV2非Upsertテーブル)のマージをオンにしますか | disable | この設定項目を有効にすると、システムは自動的にCOWテーブルに対してファイルマージタスクを生成します。 注意が必要です:COWテーブルは通常データ量が大きいため、ファイルマージ時に多くのリソースを消費する可能性があります。リソース状況やテーブルのサイズに応じて、COWテーブルのファイルマージを有効にするかどうかを選択できます。 |
smart-optimizer.written.advance.strategy | (オプション)ファイルマージ戦略 | binpack | binpack(デフォルトのマージ戦略):ファイルをappend方式でマージ条件を満たすデータファイルをより大きなデータファイルにマージします。
sort:sort戦略では、指定されたフィールドに基づいてソートが行われます。業務シナリオに応じて、クエリ条件として頻繁に使用されるフィールドをソートフィールドとして選択でき、マージ後にクエリ性能が向上します。 |
smart-optimizer.written.advance.sort-order | (オプション)ファイルマージ戦略がsortの場合、設定するsortソートルール | - | Upsertテーブルでソート戦略を設定していない場合、設定されたupsertキー値(デフォルトでは最初の2つのキー値)をASC NULLS LAST方式でソートします。COWテーブルでsortマージ時にソート戦略が見つからない場合、binpackデフォルトマージ戦略が採用されます。 |
smart-optimizer.written.advance.remove-orphan-interval-min | (オプション)孤立ファイルの削除実行周期 | 1440(24 hour) | 平台は定期的に孤立ファイルをスキャンしてクリーンアップします。実行周期が短いほど、孤立ファイルのクリーンアップがより敏感になりますが、 リソースをより多く消費する可能性があります。 |
smart-optimizer.lifecycle.enable | データライフサイクルをオンにしますか? | disable | disable:無効 enable:オン データテーブルの設定のみ有効 |
smart-optimizer.lifecycle.expiration | データライフサイクルの有効期限(単位:日) | - | データライフサイクルの有効期限。この有効期限を超えたデータは、ライフサイクルタスクによって削除される可能性があります。 |
smart-optimizer.lifecycle.expired-field | データライフサイクルの有効フィールド | - | データライフサイクルの有効フィールド。データライフサイクルが有効かどうかをチェックするためのフィールドです。このフィールドは時間形式のフィールドである必要があり、パーティションフィールドとして設定することをお勧めします。 |
smart-optimizer.lifecycle.expired-field-format | データライフサイクルの有効フィールド形式 | - | データライフサイクルの有効フィールド形式。yyyy-MM-dd、yyyyMMdd、yyyyMMddHH、yyyyMM形式をサポートしています。 |
smart-optimizer.table.expiration.enable | テーブルの有効期限をオンにしますか | disable | disable:無効 enable:オン データテーブルの設定のみ有効です。テーブル有効期限機能は、最後のスナップショット作成時間と設定された有効期限に基づいて、期限切れ時にテーブル全体を削除します。対応するテーブルにスナップショット作成行為がない場合、そのテーブルの最後のDDL時間と有効期限に基づいて、期限切れ時にテーブル全体を削除します。 |
smart-optimizer.table.expiration | テーブル有効期限設定の有効期限(単位:日) | - | データテーブル全体の有効期限。この有効期限を超えたデータは、テーブル有効期限タスクによって削除される可能性があります。 時間設定範囲は1~3650です。 |
注意:
Icebergテーブル作成時にコマンドでテーブル有効期限を設定する際、不正な動作(例えば、設定した有効期限が規定範囲外であるなど)がある場合、データテーブルの作成は成功しますが、テーブル設定は有効になりません。
最適化提案
DLCバックエンドは定期的にネイティブテーブル(Iceberg)の各指標項目を統計し、これらの指標項目に基づいて実践チュートリアルと組み合わせ、ネイティブテーブルの最適化提案を提供します。最適化提案は全部で4つの最適化提案項目に分かれており、テーブルユースケースの基本設定、データ最適化提案、およびデータストレージ分布項目の提案を含みます。
最適化提案チェック項目 | サブチェック項目 | 意味 | 業務シナリオ | 最適化提案 |
テーブル基本属性の設定チェック | メタデータガバナンスを有効にしますか? | メタデータガバナンスがオンになっているかチェックします。テーブルへの頻繁な書き込みによるメタデータ(metadata)の肥大化を防止します。 | append/merger into/upsert | オンにすることをお勧めします |
| ブルームフィルターを設定しますか? | ブルームフィルターが設定されているか確認します。ブルームフィルターテーブルを有効にした後、MORテーブルに対して削除ファイルを迅速にフィルタリングし、MORテーブルのクエリと削除ファイルのマージを高速化できます。 | upsert | 必ずオンにしてください |
| metrics の主要属性を設定しますか | metricsがfullに設定されているか確認します。この属性を有効にすると、すべてのmetrics情報が記録され、locationが長すぎるためにmetrics情報の記録が不完全になることを回避できます。 | append/merger into/upsert | 必ずオンにしてください |
データ最適化設定のチェック | 小ファイルのマージ | 小ファイルのマージがオンになっているかチェックします | merge into/upsert | 必ずオンにしてください |
| スナップショットの有効期限 | スナップショットの有効期限がオンになっているかチェックします | append/merge into/upsert | オンにすることをお勧めします |
| 孤立ファイルを削除 | 孤立ファイルの削除がオンになっているかチェックします | append/merge into/upsert | オンにすることをお勧めします |
最近のガバナンスタスクチェック項目 | 最近のガバナンスタスクチェック項目 | テーブルでデータガバナンスが有効になっている場合、システムはデータガバナンスタスクの実行状況を統計します。連続して複数のタスクがタイムアウトまたは失敗した場合、最適化が必要と判断されます。 | append/merger into/upsert | オンにすることをお勧めします |
データストレージ分布 | 平均ファイルサイズ | スナップショットのsummary情報を収集し、平均ファイルサイズを計算します。平均ファイルサイズが10M未満の場合、最適化が必要と判断されます。 | append/merger into/upsert | オンにすることをお勧めします |
| メタデータファイルサイズ | テーブルのmetadata.jsonメタファイルのサイズを収集します。このファイルサイズが10Mを超える場合、最適化が必要と判定されます。 | append/merger into/upsert | オンにすることをお勧めします |
| テーブルスナップショット数 | 収集テーブルスナップショット数。テーブルスナップショット数が1000個を超える場合、最適化が必要と判定されます | append/merger into/upsert | オンにすることをお勧めします |
テーブル属性基本設定項目の最適化提案
メタデータガバナンス方法を確認し設定する
Step1 チェック方法
`show TBLPROPERTIES` を使用してテーブルプロパティを確認し、「write.metadata.delete-after-commit.enabled」と「write.metadata.previous-versions-max」が設定されているかどうかをチェックします。
Step2 設定方法
Step1のチェック結果が未設定の場合、以下のAlter table DDLで設定できます。参考方法は以下の通りです。
ALTER TABLE`DataLakeCatalog`.`axitest`.`upsert_case`SETTBLPROPERTIES('write.metadata.delete-after-commit.enabled' = 'true','write.metadata.previous-versions-max' = '100');
説明:
メタデータの自動ガバナンスを有効にするには、属性「write.metadata.delete-after-commit.enabled」をtrueに設定する必要があります。実際の状況に応じて保持する過去のメタデータの数を設定できます。例えば、「write.metadata.previous-versions-max」を100に設定すると、最大100個の過去のメタデータが保持されます。
ブルームフィルタ方法を確認して設定する
Step1 チェック方法
「show TBLPROPERTIES」でテーブルプロパティを確認し、「write.parquet.bloom-filter-enabled.column.{column}」がtrueに設定されているかどうかをチェックします。
ステップ2 設定方法
Step1のチェック結果が未設定の場合、以下のAlter table DDLで設定できます。参考方法は以下の通りです。
ALTER TABLE`DataLakeCatalog`.`axitest`.`upsert_case`SETTBLPROPERTIES('write.parquet.bloom-filter-enabled.column.id' = 'true');
説明:
upsert シナリオで bloom をオンにし、upsert 主キーに基づいて設定することをお勧めします。複数の主キーがある場合は、最初の2つの主キーフィールドに対して設定することをお勧めします。
bloomフィールドを更新した後、上流にinlong/oceans/flinkが書き込む場合、上流のインポートジョブを再起動する必要があります。
メトリクスのキー属性を確認および設定する
Step1 チェック方法
`show TBLPROPERTIES` を使用してテーブルプロパティを確認し、「write.metadata.metrics.default」が「full」に設定されているかどうかをチェックします。
Step2 設定方法
Step1のチェック結果が未設定の場合、以下のAlter table DDLで設定できます。参考方法は以下の通りです。
ALTER TABLE`DataLakeCatalog`.`axitest`.`upsert_case`SETTBLPROPERTIES('write.metadata.metrics.default' = 'full');
データ最適化設定の最適化提案
Step1 チェック方法
SQLでチェックします。
show TBLPROPERTIES を使用してテーブルプロパティを確認し、データ最適化が設定されているかどうかをチェックします。データ最適化の属性設定値については、DLC ネイティブテーブルフォーマット説明を参照してください。
DLCコンソールで視覚的にチェックします。
Step2 設定方法
最近のデータガバナンス最適化タスク項目の最適化提案
データガバナンスが正常かどうかを確認してください
Step1 チェック方法
DLC コンソールのデータ管理モジュールに進み、データベースページに入ります。データベースを選択後、データテーブルリストページに進み、データテーブル名をクリックして最適化モニタリングに入ります。最適化タスクの中から本日の最適化を選択し、最近3時間以内に実行失敗したタスクがないか確認します。存在する場合、この項目のチェックは不合格となります。失敗したタスクを選択し、詳細を表示の中の実行結果を確認してください。
Step2 修正方法
シナリオデータ最適化タスクの実行失敗の原因と対処方法のまとめ。
1. データガバナンスの設定エラーにより実行が失敗しました。
sort マージ戦略を有効にしましたが、ソートルールの設定が間違っているか、存在しないソートルールが設定されています。
データガバナンス用に設定されたエンジンが変更されたため、ガバナンスタスクの実行時に適切なエンジンが見つかりませんでした。
2. タスクの実行がタイムアウトしました。
説明:
最近のデータ最適化タスクの実行状況を確認し、修復後は3時間待ってから回復しているかどうかを観察する必要があります。
データストレージ分布項目の最適化提案
説明:
このシナリオのチェックが通らない場合、通常はデータ量が大きいため、まず手動で処理してからデータ最適化管理に追加することを検討することをお勧めします。
パフォーマンスがより高いSparkジョブエンジンで処理することをお勧めします。
手動での小ファイル結合処理を行う際、target-file-size-bytesパラメータは業務シナリオに基づいて設定します。upsert書き込みの場合は134217728(128M)を超えないことを推奨し、append/merge into書き込みの場合は536870912(512M)を超えないことを推奨します。
スナップショットの有効期限切れをsparkジョブエンジンで実行する場合、max_concurrent_deletesパラメータを大きく調整できます。
データファイル平均サイズチェック不合格の対処方法
Step1 原因のまとめ
データファイル平均サイズが小さすぎる場合、通常は以下のような状況で発生します:
テーブルパーティションの分割が細かすぎて、各パーティションに少量のデータしか含まれていません。
テーブルにInsert into/overwrite方式で書き込む際、上流データが分散している場合、例えば上流データもパーティションテーブルで、かつパーティション内のデータ量が少ない場合。
テーブルにmerge into方式でMORテーブルに書き込みますが、小ファイルのマージが行われていません。
テーブルにupsert方式で書き込みますが、小ファイルのマージが行われていません。
Step2 修正方法
以下のSQLを参考に、手動で小ファイルのマージを実行してください。
CALL `DataLakeCatalog`.`system`.`rewrite_data_files`(`table` => 'test_db.test_tb',`options` => map('delete-file-threshold','10','max-concurrent-file-group-rewrites', --実際のリソース状況に応じて決定します。並列度が高いほど、使用するリソースが増え、ファイルの結合が速くなります'5','partial-progress.enabled','true','partial-progress.max-commits','10','max-file-group-size-bytes','10737418240','min-input-files','30','target-file-size-bytes','134217728'))
MetaData メタファイルサイズチェック不合格の対処方法
Step1 原因のまとめ
MetaData メタファイルが大きすぎる場合、通常はデータファイルの数が多すぎることが原因で、主に以下のような理由が考えられます:
テーブルが長期間にわたってappend書き込みを行い、かつ毎回の書き込みで分散されるファイル量が多い。
テーブル属性がMORテーブルで、長期間にわたってmerge into書き込みを行っていますが、小ファイルのマージが有効になっていません。
テーブルが長期間にわたってスナップショットの期限切れ処理を行っておらず、テーブルが大量の履歴スナップショットデータファイルを保持しています。
テーブルのパーティションが大きく、各パーティションのファイルが小さく数が多いです。
Step2 修正方法
手動で小ファイルのマージを実行することを参照してください。
以下のSQLを参考に、手動で期限切れスナップショットSQLを実行し、履歴スナップショットをクリーンアップしてください。
--sparkジョブエンジンの期限切れスナップショットリファレンスを採用CALL `DataLakeCatalog`.`system`.`expire_snapshots`(`table` => 'test_db.test_tb',`retain_last` => 5,`stream_results` => true,`older_than` => TIMESTAMP '2024-01-10 13:02:40.407', --テーブルの実際のスナップショットに基づく有効期限`max_concurrent_deletes` => 50);--spark sqlエンジンの期限切れスナップショットリファレンスを採用CALL `DataLakeCatalog`.`system`.`expire_snapshots`(`table` => 'test_db.test_tb',`retain_last` => 5,`stream_results` => true,`delete_by_executor` => true,`older_than` => TIMESTAMP '2024-01-10 13:02:40.407', --テーブルの実際のスナップショットに基づく有効期限`max_concurrent_deletes` => 4)
業務シナリオに合わせて、書き込むファイルをある程度集約し、ファイルの分散を防ぎます。
データが `insert into` または `insert overwrite` で書き込まれる場合、以下の方法で自動的に `rebalance` 操作を追加できます(エンジンを2025-07-11以降のバージョンにアップグレードする必要があります):
`spark.sql.adaptive.insert.repartition`:このパラメータはデフォルトで `false` に設定されており、手動で `true` に設定する必要があります。エンジンレベルのグローバル静的設定として、Hiveテーブルにのみ有効です(Icebergテーブルには適用されません)。有効にすると、システムは書き込み前に自動的に `rebalance` オペレータを挿入し、小さいファイルを集約します。
スナップショット数のチェック不合格の処理方法
Step1 原因のまとめ
長期間スナップショットの有効期限が切れていません。
upsert 書き込みチェックポイントの周期が不合理で、大量のスナップショットが生成されます。
Step2 修正方法
スナップショットの有効期限切れ実行SQLを参考に、スナップショットの有効期限切れを実行してください。
Flink書き込みのcheckpoint周期を調整し、DLCネイティブテーブルのupsert書き込みcheckpoint周期は3〜5分に設定することをお勧めします。
データ最適化の典型的なシナリオ設定参考
シーン1:ファイルのマージをオンにせず、ファイルのクリーンアップのみをオンにする
使用シナリオ
データテーブルがAppend方式で書き込まれる場合、Sparkエンジンのinsert into/overwrite、flink/inlongオフライン書き込みが含まれます。このシナリオでは書き込み時にファイルが既に十分に集約されているため、データ最適化によるデータ結合は不要で、ファイルのクリーンアップのみを有効にすれば十分です。
設定参考
説明:
1. append書き込み方式のファイルも小さい場合、実際の状況に応じてファイルの結合を有効にし、目標ファイルサイズを調整することができます。append書き込みのテーブルディレクトリファイルサイズは512MBに設定することをお勧めします。
2. ユーザーがインデックスを構築する必要がある場合、ファイルのマージを有効にし、マージ戦略を「sort」に設定することもできます。
シーン2:ファイルの結合をオンにし、同時にファイルのクリーンアップをオンにする
使用シナリオ
データテーブルがV2バージョンで、Upsert方式およびmerge into方式で書き込まれる場合、通常はflink/inlongのupsert方式で書き込まれます。このシナリオではDeletesファイルが書き込まれるため、データ最適化による事前処理が必要です。そうしないとクエリ性能に影響を与える可能性があります。
設定参考
説明:
ユーザーがインデックスを構築する必要がある場合、ファイルのマージを有効にし、マージ戦略を「sort」に設定することもできます。
シナリオ3:データ最適化戦略は上位から継承され、テーブルレベルのライフサイクルを個別に有効化する
使用シナリオ
ユーザーにはテーブルのライフサイクル設定に関する要件があります。
設定参考
説明:
ライフサイクル設定とデータ最適化設定は独立して設定できます。ユーザーはデータ最適化をデータベースに、ライフサイクル設定をテーブルにそれぞれ設定することで、各テーブルごとにデータ最適化戦略を個別に設定する手間を削減できます。
シナリオ4:テーブルレベルのテーブル有効期限機能を個別に有効化する
使用シナリオ
DLCのメタデータ管理機能には上限があります。顧客が使用中に高頻度で一時テーブルを生成する場合があり、これらのテーブルが長期間残存するとメタデータスペースを継続的に占有し、最終的にメタデータ上限の閾値をトリガーします。その結果、新規テーブル作成やメタデータの読み書きなどのコア操作が失敗する可能性があります。直接手動で削除コマンドを実行すると、テーブル数が多すぎる、メタデータロックの競合、権限異常などの問題により削除が失敗し、リソースを効果的に解放できない場合があります。さらに、メタデータサービスの遅延を引き起こす可能性もあります。
コンソール設定参考
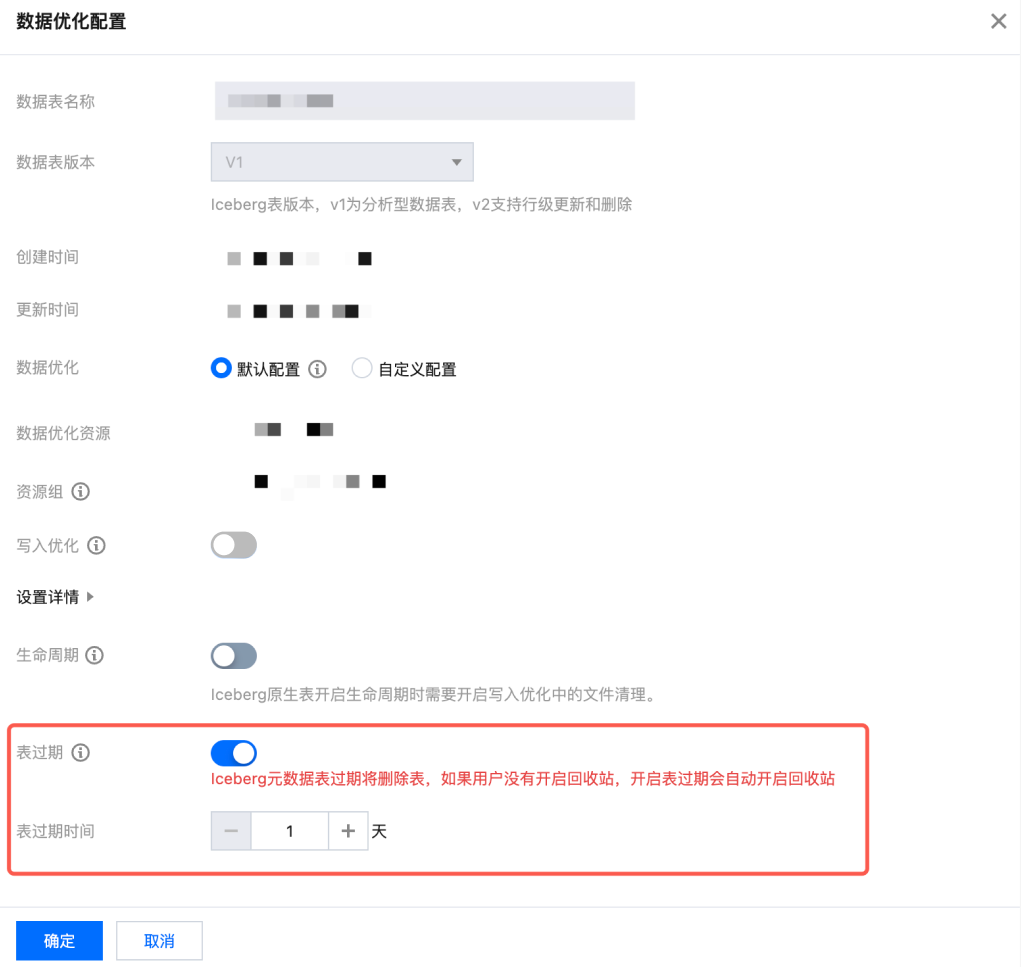
SQL文による設定参考
ALTER TABLE dbName.tableName SET TBLPROPERTIES ('smart-optimizer.table.expiration.enable' = 'enable','smart-optimizer.table.expiration' = '30');
Icebergのネイティブテーブル有効期限機能は、最後のスナップショット作成時間と設定した有効期限に基づき、期限切れ後にテーブル全体を削除します。メタデータ管理 > データベース > データテーブル > 最適化監視 > スナップショットリストから、最後のスナップショット作成時間を取得できます。
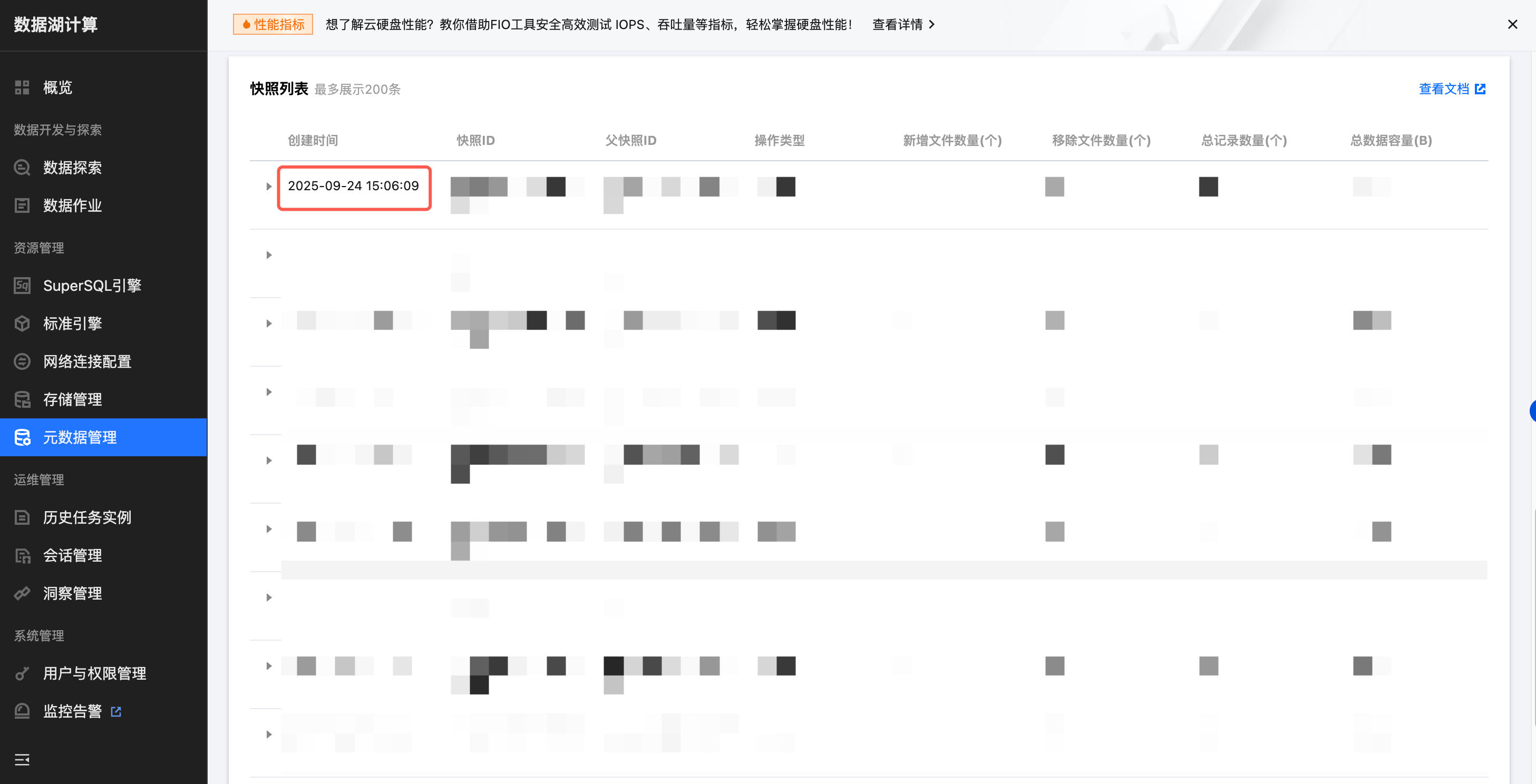
または、以下のSQL文を使用してデータ探索で標準エンジンを用い、対応するテーブルの最後のスナップショット作成時間をクエリできます:
SELECTto_timestamp (committed_at) AS last_snapshot_create_timeFROM`catalog_name`.`db_name`.`table_name`.snapshotsORDER BYsnapshot_id DESCLIMIT1
注意:
フィードバック