The data processing feature of the TDMQ for CKafka (CKafka) connector provides the capability to extract message content based on regular expressions. Extraction based on regular expressions uses the open-source regular expression extraction package re2.
Java's standard regular expression package java.util.regex and other widely used regular expression packages, such as PCRE, Perl RE, and Python (re), all use a rollback policy. That is, when a pattern presents two alternatives a|b, the engine will first attempt to match the subpattern a. If the match fails, it will reset the input stream and attempt to match the subpattern b.
If this matching pattern is deeply nested, then this policy requires exponentially nested parsing of the input data. If the input string is long, the matching time can tend towards infinity.
In contrast, the RE2J algorithm achieves regular expression matching in linear time by using a non-deterministic finite automaton to simultaneously check all matching items during a single parse of the input data.
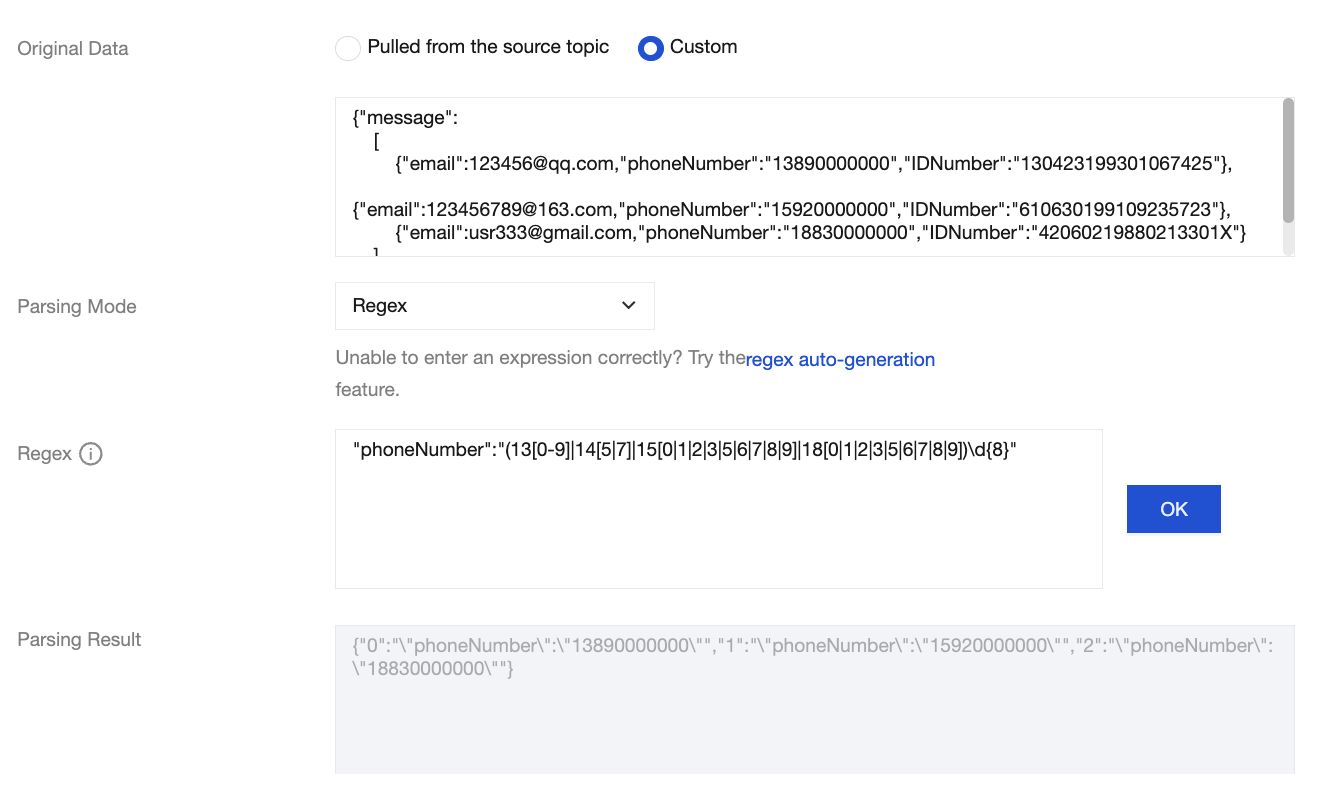
Regular expression extraction in data processing is suitable for extracting specific fields from long-array messages. This document describes how to use the regular expression auto-generation feature provided by CKafka and several common extraction patterns.
Automatically Generating Regular Expressions
Regular expression auto-generation is applicable to the log parsing pattern, where each line in the log text represents a raw log entry, and each log can be extracted into multiple key-value pairs using regular expressions.
When configuring the single-line full regular expression pattern, you need to first input a log sample and then customize a regular expression. After the configuration is completed, the system will extract corresponding key-value pairs based on the capture groups in the regular expression.
This section describes how to collect logs in single-line full regular expression pattern.
Prerequisites
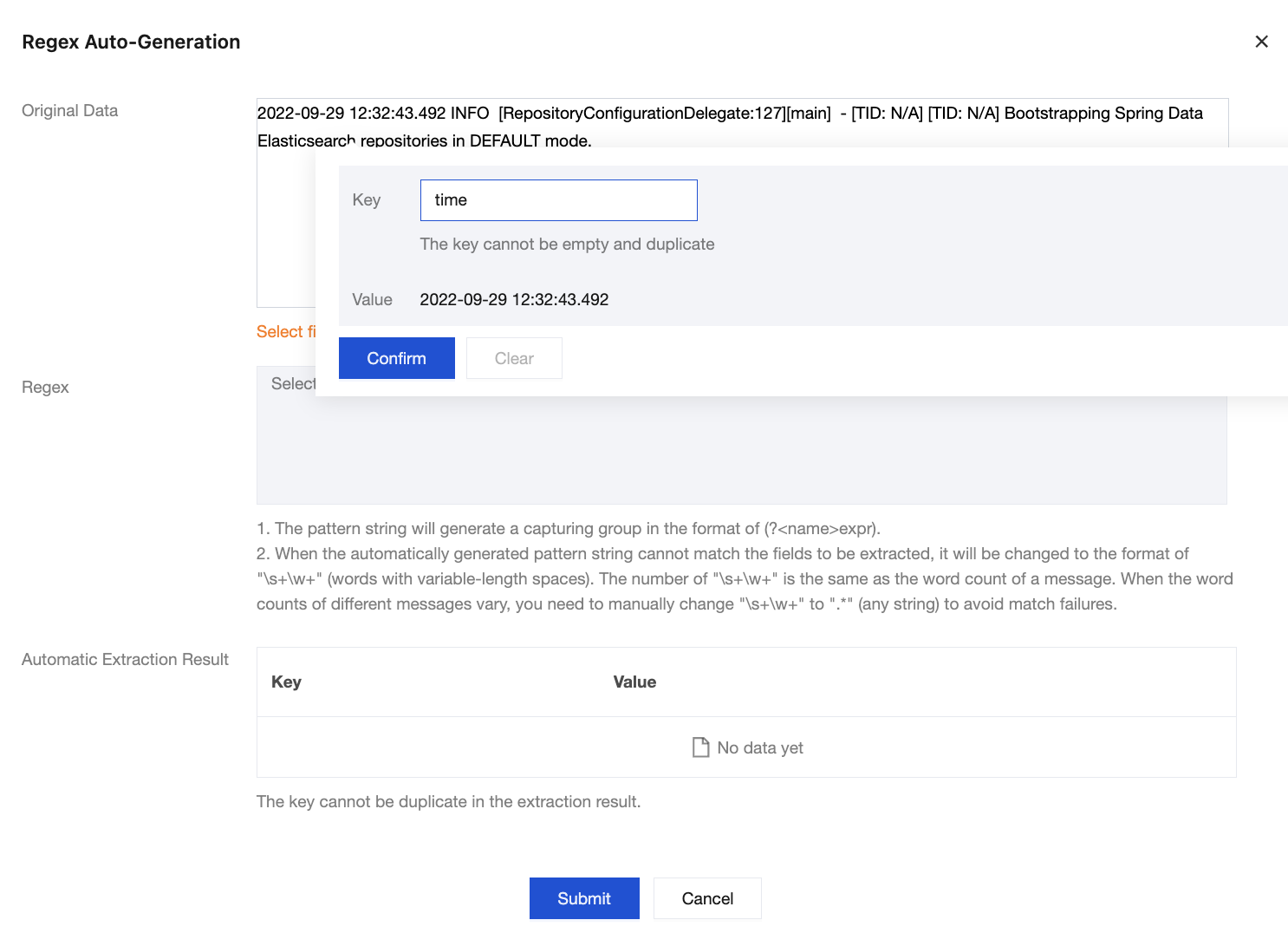
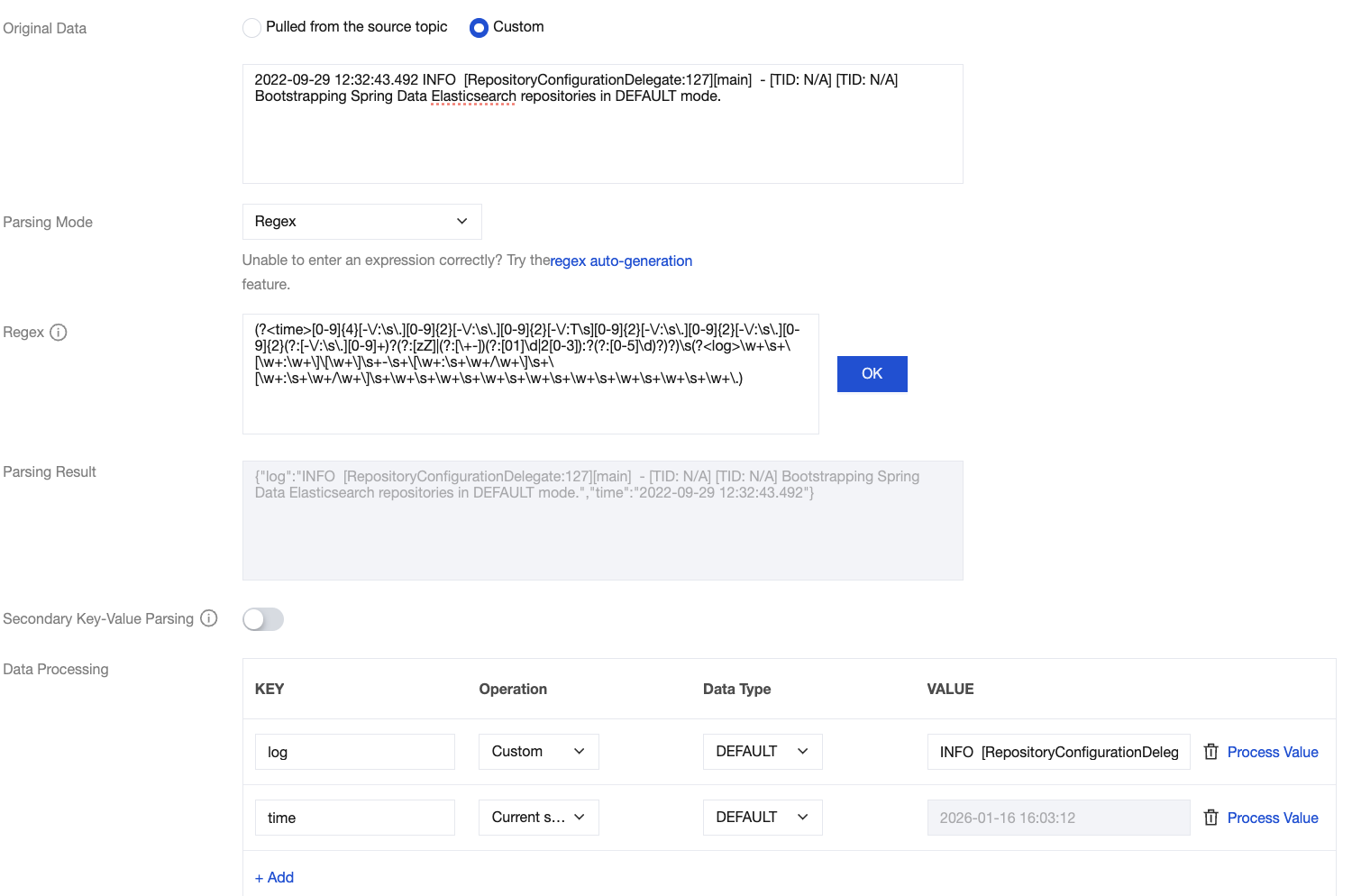
Assume the raw data of a log is:
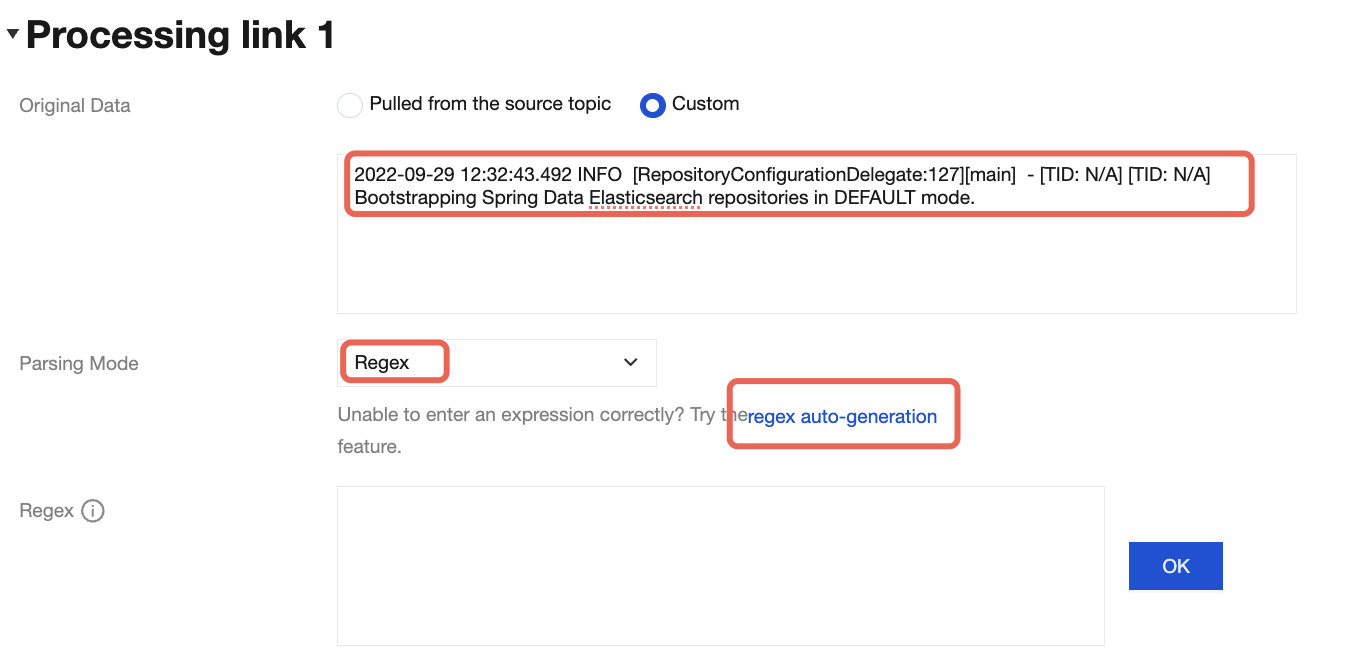
2022-09-29 12:32:43.492 INFO [RepositoryConfigurationDelegate:127][main] - [TID: N/A][TID: N/A] Bootstrapping Spring Data Elasticsearch repositories in DEFAULT mode.
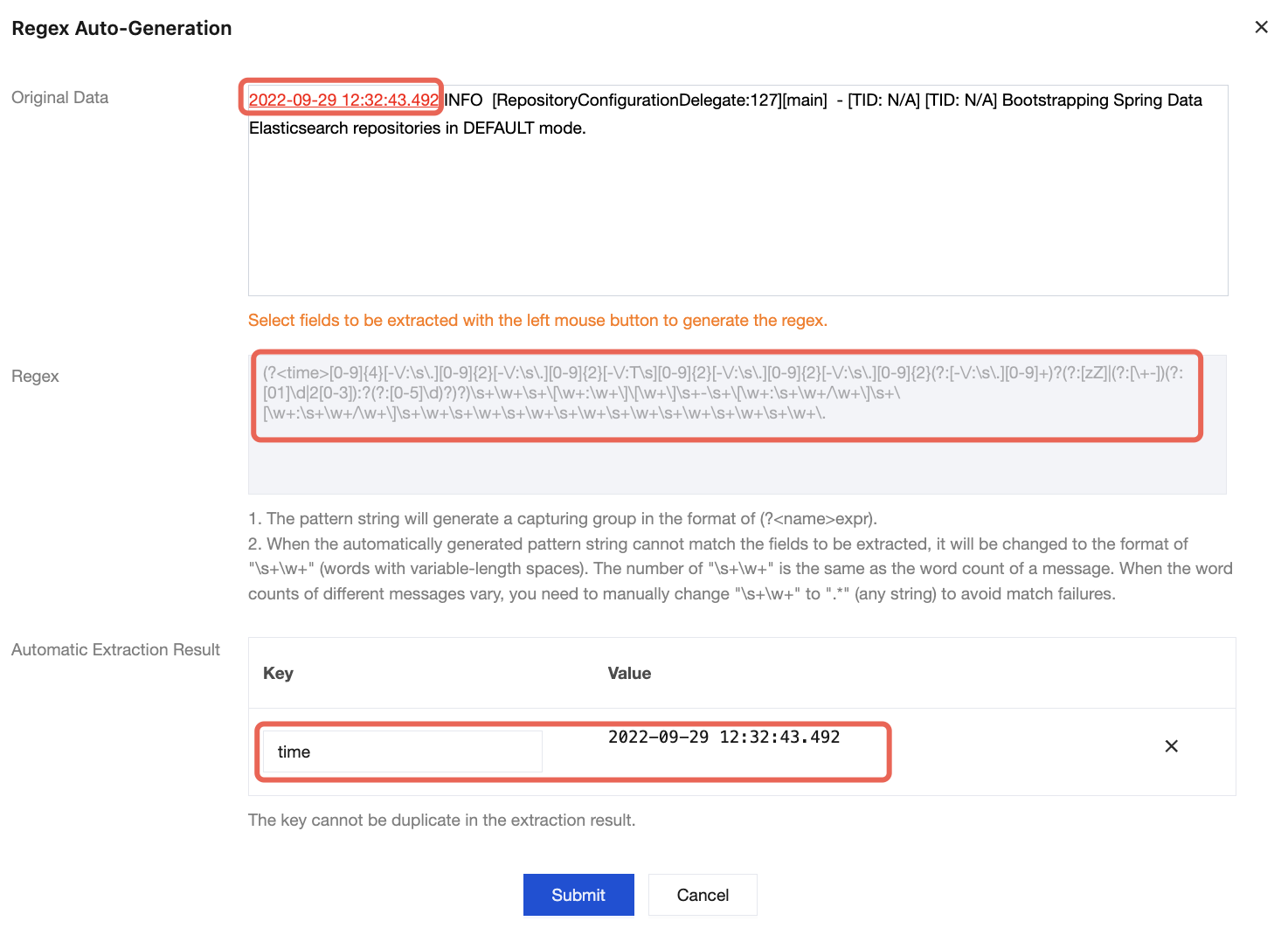
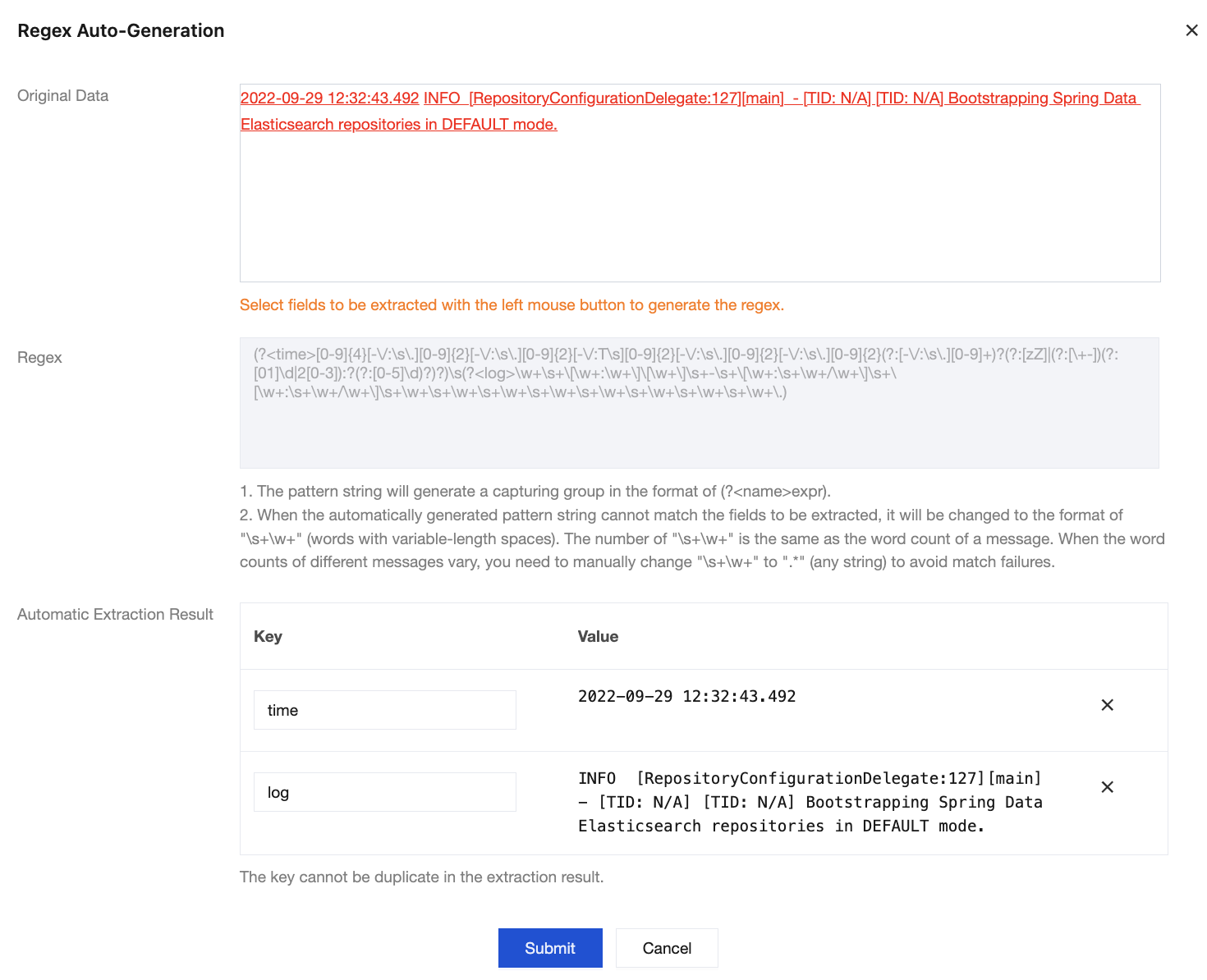
After the system extracts the corresponding key-value pair based on the () capture groups, you can customize the key name of each group as follows:
{"time":"2022-09-29 12:32:43.492",
"log":"INFO [RepositoryConfigurationDelegate:127][main] - [TID: N/A] [TID: N/A] Bootstrapping Spring Data Elasticsearch repositories in DEFAULT mode."}
Operation Steps
1. On the page for data processing rule configuration, enter a log sample in the Raw Data field, set the parsing pattern to Regex Extraction, and click Auto-Generate Regular Expression under Parsing Pattern.
2. In the pop-up Auto-Generate Regular Expression modal view, select the log content from which you want to extract key-value pairs according to your actual search and analysis needs. Then, enter the key name in the text box and click Submit.
3. The system will automatically extract a regular expression for this portion of content, and the auto-extraction results will appear in the key-value table.
4. Repeat Step 2 until all key-value pairs are extracted.
5. Click Submit, and the system will automatically generate a complete regular expression based on the extracted key-value pairs.
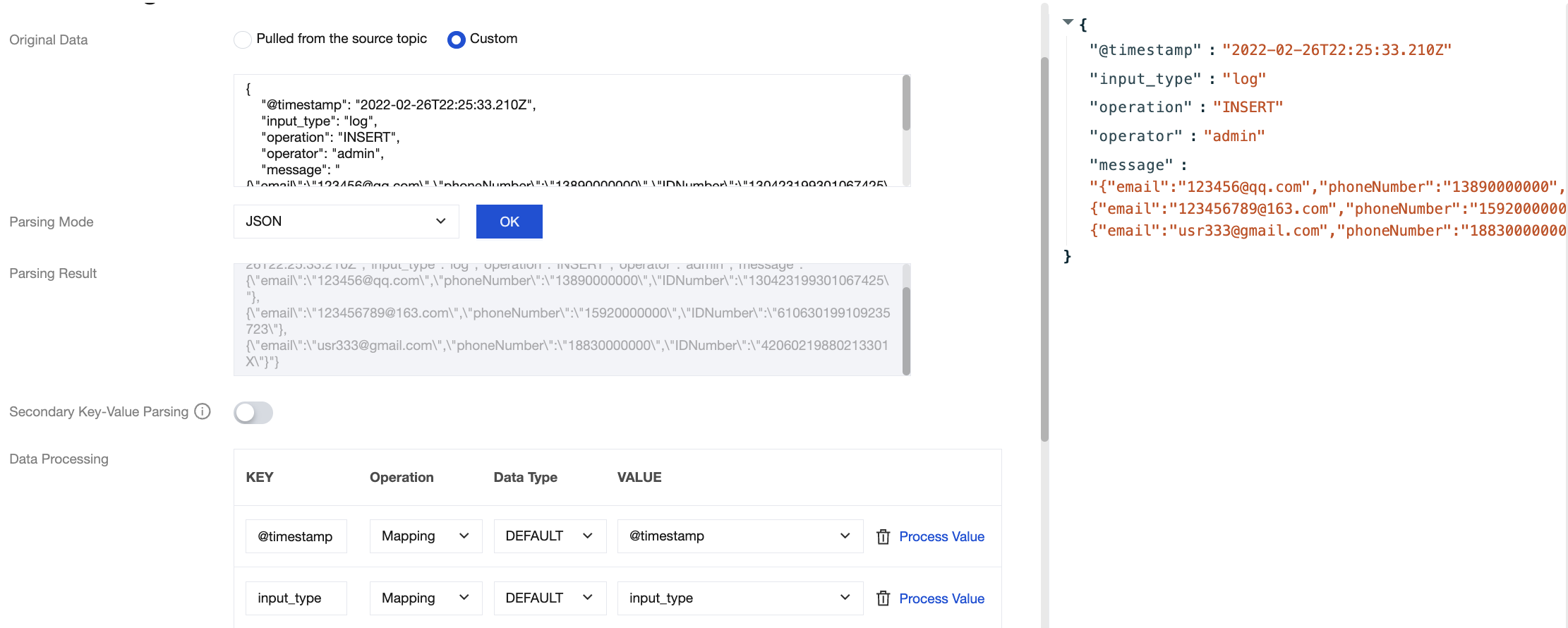
Here, processing is performed through multiple processing chains. The processing result of chain 1 is as follows:
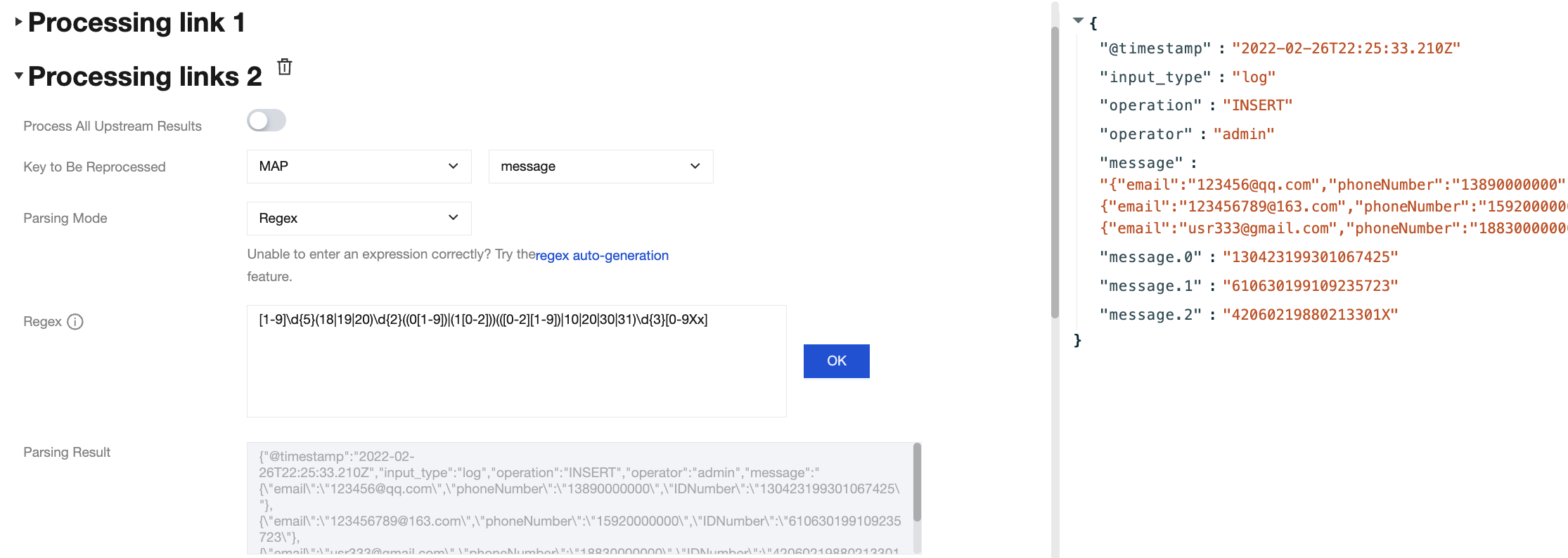
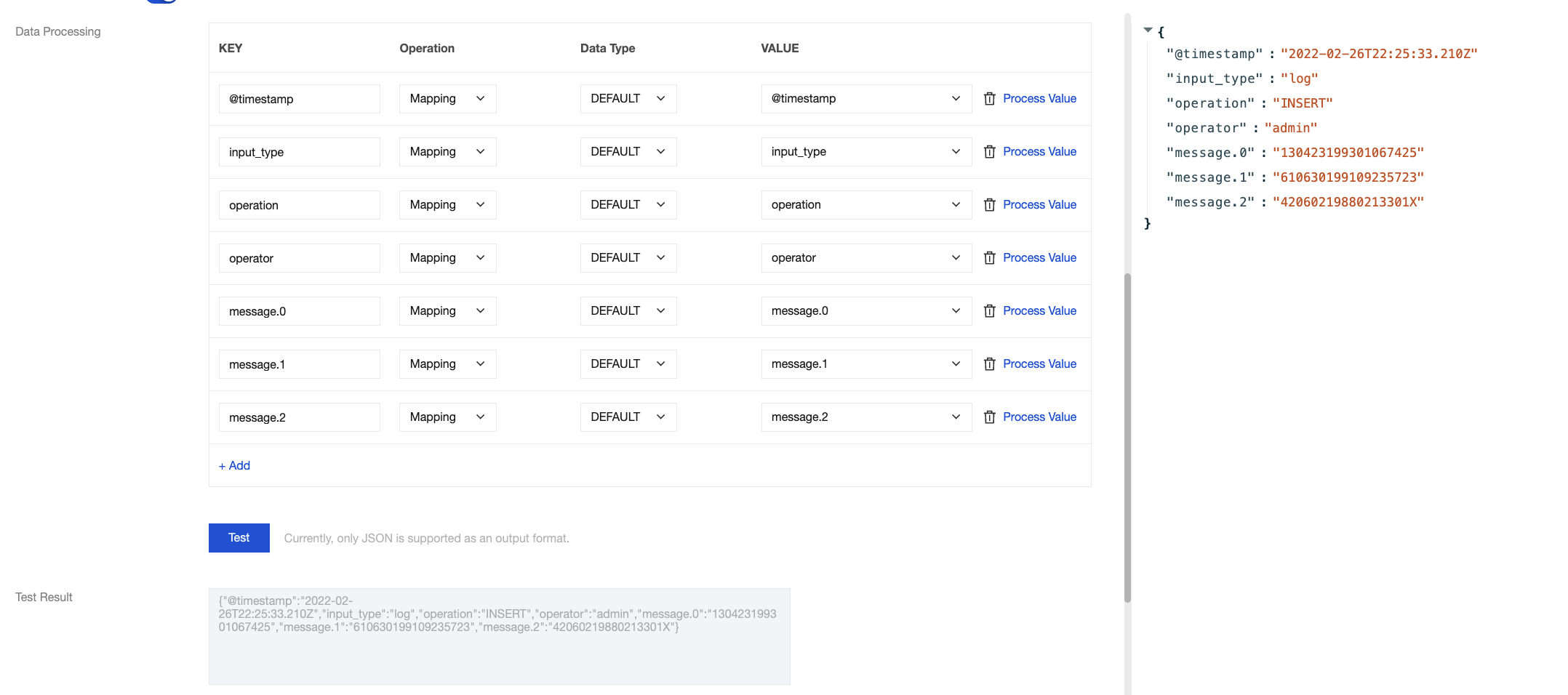
At this point, secondary processing is required for the message field. The processing result of chain 2 is as follows:
Processing result:
{
"@timestamp":"2022-02-26T22:25:33.210Z",
"input_type":"log",
"operation":"INSERT",
"operator":"admin",
"message.0":"130423199301067425",
"message.1":"610630199109235723",
"message.2":"42060219880213301X"
}
The required ID Number fields were extracted, the original message field was deleted, and the required external fields, such as operation and the N required data items from the message, were retained.