集群高可靠
Download
聚焦模式
字号
消息队列 CKafka 版提供集群级高可用能力,通过跨可用区部署和实例可用区迁移功能,有效提升消息服务的稳定性和容灾能力。
集群级高可用能力说明
高可用能力 | 适用版本 | 说明 | 参考文档 |
跨可用区部署 | Serverful 高级版与专业版 Serverless 形态 | 在拥有3个或3个以上可用区的地域购买 CKafka Serverful 实例时,可以选择多个可用区进行部署,分区副本会强制分布在各个可用区节点上,这种部署方式能够让您的实例在单个可用区不可用情况下仍能正常提供服务。 Serverful 专业版可以最多选择四个可用区。 Serverful 高级版最多可以选择两个可用区。 CKafka Serverless 实例仅需选择地域,系统自动跨可用区部署,简化配置并保障高可用。 | |
变更实例可用区 | Serverful 专业版 | 将实例迁移至同一地域内的其它可用区。迁移可用区后,实例的所有属性、配置和连接地址都不会改变。 从一个可用区迁移至另一个可用区:实例所在可用区出现满负载或者其它影响实例性能的情况。 从一个可用区迁移至多个可用区:提高实例的容灾能力,实现跨机房容灾。 |
跨可用区部署
部署架构
CKafka 的跨可用区部署架构分为网络层、数据层和控制层。
网络层
CKafka 会为客户端暴露一个 VIP,客户端在连接到 VIP 后,会拿到主题分区的元数据信息(该元数据通常是地址,会通过同一个 VIP 的不同 port 进行一一映射)。这是一个可以随时 failover 到另一个可用区的 VIP,当某个可用区不可用时,该 VIP 会自动漂移到该地域另一个可用的节点,从而实现跨可用区容灾。
数据层
CKafka 数据层和原生 Kafka 采用相同的分布式部署方式,即多个数据副本分布在不同 Broker 节点,不同节点会部署在不同可用区。在处理某个分区时,不同的节点之间会有 Leader-follower 的关系,当 Leader 发生异常不在线时,集群控制节点(Controller)会选举出新的分区 Leader 来承接这个分区的请求。
对于客户端来说,当某个可用区出现异常不可用后,如果某个主题分区的 Leader 位于不可用区 Broker 节点上,则原先建立的相关连接会出现超时或者连接被关闭的情况,当该分区 Leader 节点异常之后,Controller(若 Controller 节点异常,剩余节点会竞选出新的 Controller 节点)会选举出新的 Leader 节点提供服务,Leader 切换 时间在秒级(具体切换时间与集群节点个数,元数据大小成正比)。客户端会定时刷新主题分区元数据信息,连接新的 Leader 节点进行生产消费。
控制层
CKafka 的控制层和原生 Kafka 采用相同的技术方案,依赖 ZooKeeper 对 Broker 节点进行服务发现和集群 Controller 选举。支持跨可用区部署的 CKafka 实例,其中 ZooKeeper 集群 zk 节点(以下简称 zk 节点)部署在三个可用区(或机房)。当其中任意一个可用区的 zk 节点出现故障断连,整个 zk 集群仍可以正常提供服务。
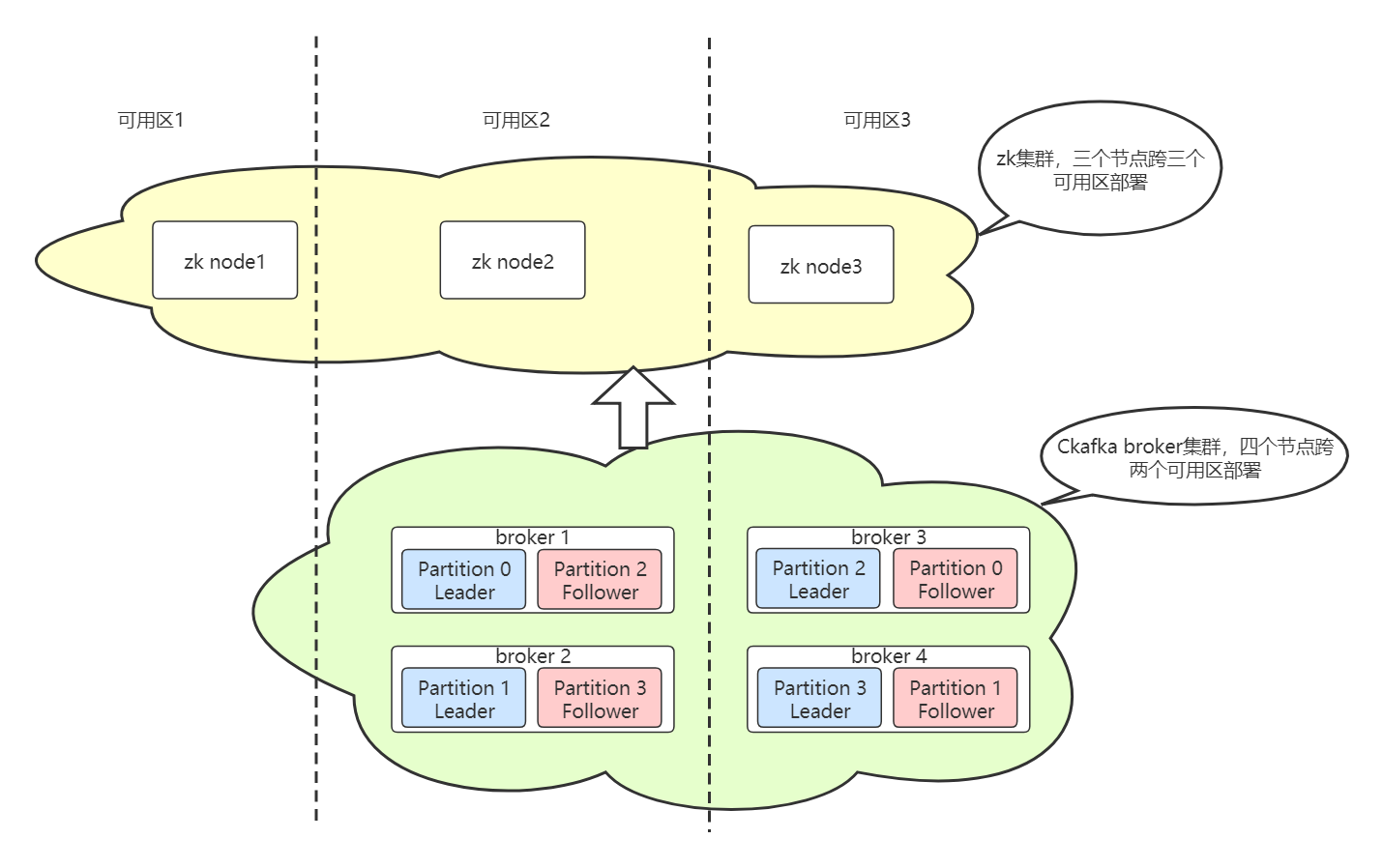
跨可用区部署优劣势
优势
可以大幅度提升集群的容灾能力,当单个可用区出现意外的网络不稳定、断电重启等不可抗力风险时,仍能保证客户端在短时间等待重连后恢复消息的生产和消费。
劣势
如果采取跨可用区部署,由于分区副本分布在多个可用区上,故消息复制相比单个可用区存在额外的跨区网络时延,该时延会直接影响到生产(客户端 ACK 参数大于1,或者等于-1,all)的客户端写入耗时。目前广州、上海、北京几个主要地域跨可用区的时延一般为10ms - 40ms。
跨可用区部署场景解析
单 AZ 不可用
单个 AZ 不可用后,如前文对原理的解析,客户端会出现断连重连,重连后服务仍能正常提供。
由于管控 API 服务目前不支持跨可用区部署,所以在单个 AZ 不可用之后,可能出现无法通过控制台创建 Topic,配置 ACL 策略,查看监控等现象,但不会影响存量业务的生产消费。
两个 AZ 网络隔离
如果两个 AZ 之间出现网络隔离,即无法相互通信,则可能会出现集群脑裂的现象,即两个可用区的节点都提供服务,但其中一个可用区的数据写入会在集群恢复后视为脏数据。
考虑如下场景,当集群 Controller 节点和 zk 集群一个 zk 节点与其他节点发生网络隔离。此时,其他节点会重新竞选产生新的 Controller(因为 zk 集群多数节点网络通信正常,则 Controller 可以竞选成功)但是发生网络隔离的 Controller 仍然认为自己是 Controller 节点,这时候集群会出现脑裂的情况。
此时客户端的写入需要分情况考虑,这里举个例子,当客户端的 ACK 策略等于 -1 或者 all,副本数为2时,假设集群是3节点,脑裂之后会2:1分布,原先 Leader 在1节点地域的分区写入会报错,另一边则会正常写入。而一旦是3副本且配置了 ACK=-1 或者 all,则两边都不会写入成功。这时就需要根据具体参数配置来确定进一步的处理方案。
在集群网络恢复后,客户端无需做操作即可恢复生产消费,但是由于服务端会重新对数据进行归一化,其中一个分裂节点的数据会被直接截断,但对于多副本跨区的数据存储方式来说,这种截断也并不会带来数据丢失。
多 AZ 容灾限制
容量限制
CKafka 是通过底层资源多 AZ 分布实现多 AZ 容灾。AZ 故障情况下,CKafka 会将 Partition Leader 切换到可用 AZ 的 Broker 节点中,所以承载流量的底层资源会变少,因此会有容量问题。以下是单 AZ 故障资源可用情况:
2 AZ 容灾实例,可使用容量 = 实例 / 2,为保证正常使用,客户需冗余 100% 的资源。
3 AZ 容灾实例,可使用容量 = 实例 / 3 * 2,为保证正常使用,客户需冗余 50% 的资源。
4 AZ 容灾实例,可使用容量 = 实例 / 4 * 3,为保证正常使用,客户需冗余 33.3% 的资源。
n AZ 容灾实例,可使用容量 = 实例 / n * (n - 1),为保证正常使用,客户需冗余 1 / (n - 1) 的资源
实例参数配置限制
CKafka 支持在控制台修改 Topic 级别的配置
min.insync.replicas,该配置在客户端设置 ACK=-1 时生效,可以确保一条消息被 min.insync.replicas 个副本同时同步才返回生产成功(如:Topic 副本=3,min.insync.replicas=2,则需要生产消息至少被 2 个副本同步才算成功)。所以 Topic 的配置 (
min.insync.replicas < AZ 数),才能保证 AZ 故障情况下生产可用性;Topic 的配置 min.insync.replicas < Topic副本数才能保证单节点故障下生产可用性。设置规则为:min.insync.replicas < Topic 副本数 <= AZ 数2 AZ 实例,Topic 副本数 = 2,min.insync.replicas = 1
3 AZ 实例,Topic 副本数 = 2,min.insync.replicas = 1
3 AZ 实例,Topic 副本数 = 3,min.insync.replicas <= 2
客户端参数配置限制
当您使用多 AZ 容灾部署的 CKafka 实例时,如果某个可用区发生故障,新启动的客户端在首次连接时可能会解析到故障节点。为了让客户端能够快速重连到健康节点,不同编程语言的客户端需要进行相应的参数配置。相关信息详见Kafka 网络连接超时配置。
Java 客户端
2.7.0 之前版本:连接超时时间为120s,重连速度较慢;
2.7.0 及以上版本:支持
socket.connection.setup.timeout.ms (默认值为10s)参数控制连接超时。在客户端负载相对可控且对 AZ 故障后恢复时间有诉求时,建议将 socket.connection.setup.timeout.ms 设置到 2 - 5s,可以在故障发生时更快地重试连接到健康节点。参数详见 Java SDK 实践教程。C++ 客户端 (librdkafka)
1.9及以上版本 librdkafka 客户端支持
socket.connection.setup.timeout.ms (默认值为30s)参数控制连接超时。在客户端负载相对可控且对 AZ 故障后恢复时间有诉求时,建议将 socket.connection.setup.timeout.ms 设置到 2 - 5s,可以在故障发生时更快地重试连接到健康节点。参数详见 librdkafka SDK 实践教程。Go 客户端
Confluent Go:参考 librdkafka 设置;
Sarama Go:支持
config.Net.DialTimeout (默认值为30s)参数控制连接超时。在客户端负载相对可控且对 AZ 故障后恢复时间有诉求时,建议将 config.Net.DialTimeout 设置到 2 - 5s,可以在故障发生时更快地重试连接到健康节点。参数详见 Sarama Go 实践教程。Python 客户端
Python 的 kafka-python 客户端会自动进行 DNS 查找和秒级重试,无需额外配置。
文档反馈