动态发布记录(2026年)
变量使用
数据开发的变量使用分为三个层级,分别是项目级别、工作流级别、任务级别,不同级别的变量覆盖范围不同:
项目级别:项目内的开发脚本、数据工作流、任务节点都可以使用。
工作流级别:数据工作流与其工作流内的任务节点可以使用。
任务级别:仅开发脚本与编排空间中的任务节点可以创建使用。
优先级:对于同名的变量来说,上游任务传递 > 任务级别 > 工作流级别 > 项目级别。
项目级别
变量配置
变量使用
通过开发空间创建的脚本文件与编排空间中创建的计算任务都可以使用项目变量。这里以 SQL 脚本举例:
1. 在 SQL 脚本中单击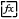
2. 在代码中引用自定义变量的变量名,格式如下:${ key }
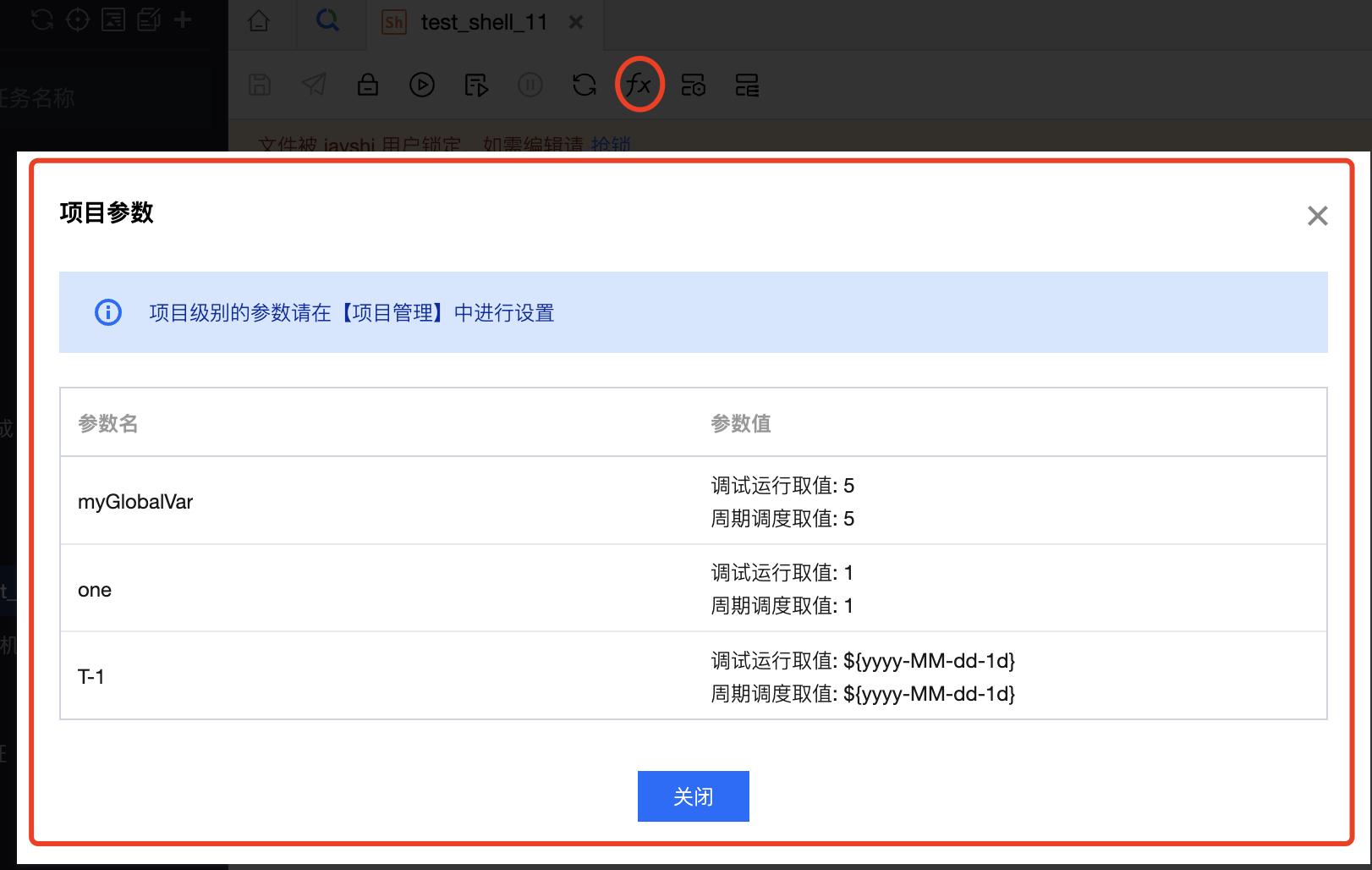
SELECT * from demo_bi.hive_userwhere id=${one} #这里的 ${one} 引用了全局变量中的 one
3. 从图中可以看到引用 one 全局变量后,SQL 执行时获取到了变量的 value 值。
工作流级别
变量配置
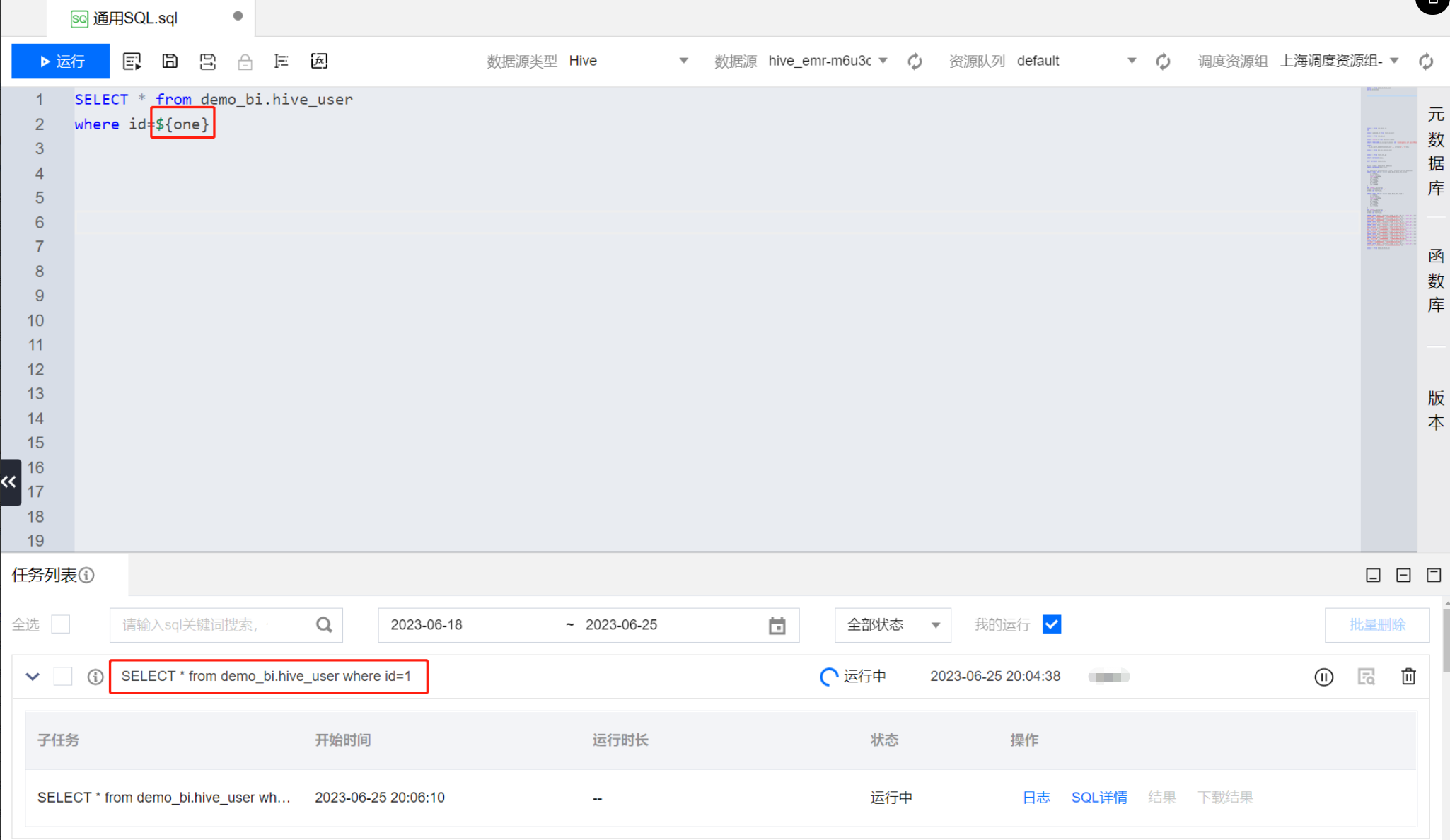
工作流级别变量应用于对应工作流中创建的计算任务节点。通过工作流画布页面右侧的通用设置,可以定义工作流变量。
变量使用
在数据工作流中创建计算任务节点,进入任务节点配置页面后,即可在配置过程中使用工作流变量。下述在 demo_workflow 工作流中配置变量,并使用工作流中的 Hive SQL 计算任务举例:
1. 在 demo_workflow 工作流的通用设置配置以下工作流参数。

2. 再进入工作流中的 Hive SQL 计算任务,在代码中引用工作流参数的变量名,格式为:${key}
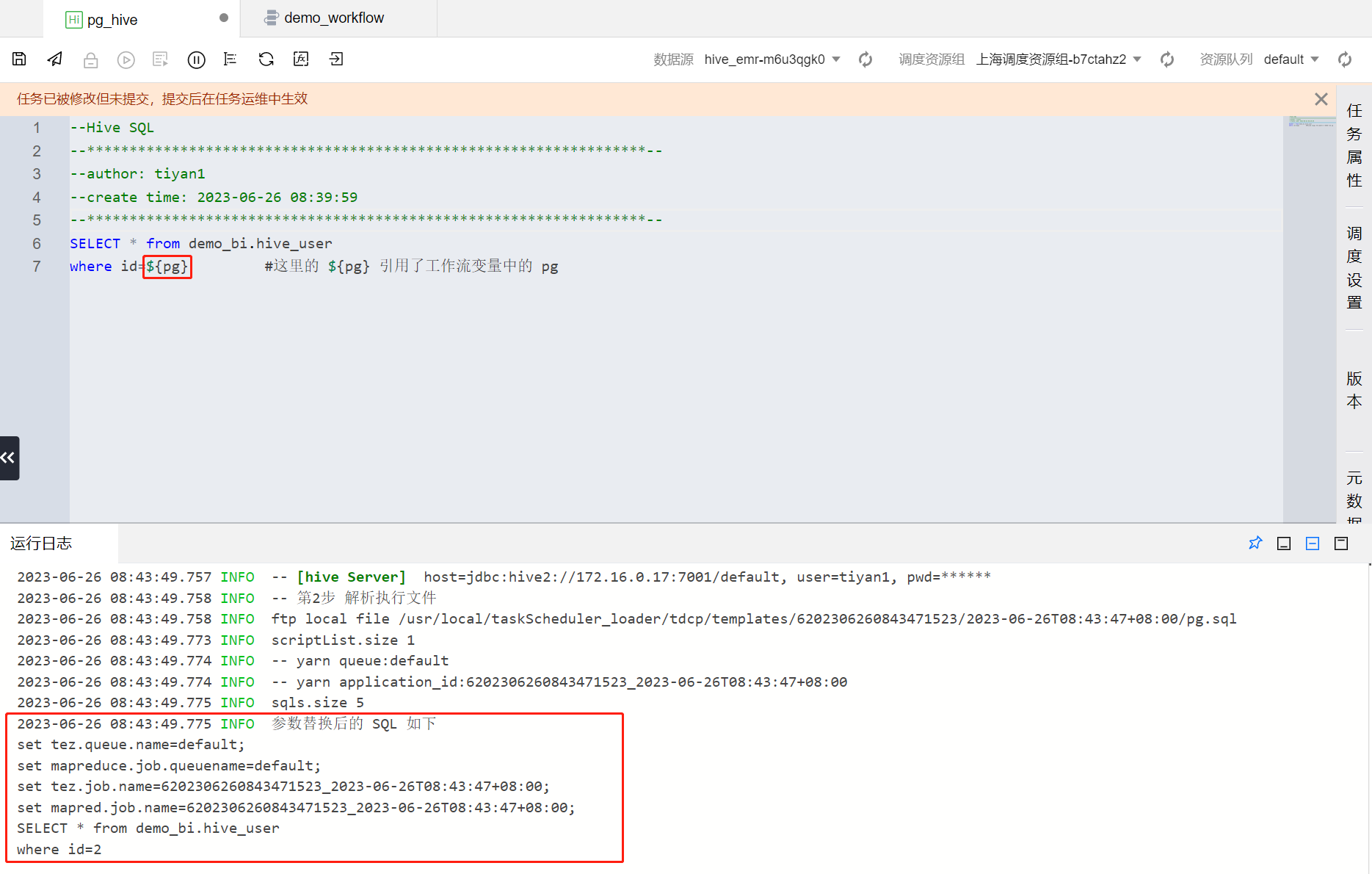
SELECT * from demo_bi.hive_userwhere id=${pg} #这里的 ${pg} 引用了全局变量中的 pg
3. 从图中可以看到计算任务中引用了工作流变量 pg 后,相应代码在运行时进行了参数替换。
任务级别
变量配置
任务级别变量应用于数据工作流中的计算任务节点,每个计算任务都可以独立配置适用于自身的任务变量。通过计算任务配置页面右侧的任务属性,可以定义对应任务的任务变量。
变量使用
进入计算任务节点,在任务属性的调度参数栏中配置任务变量。下述以 Hive SQL 任务举例:
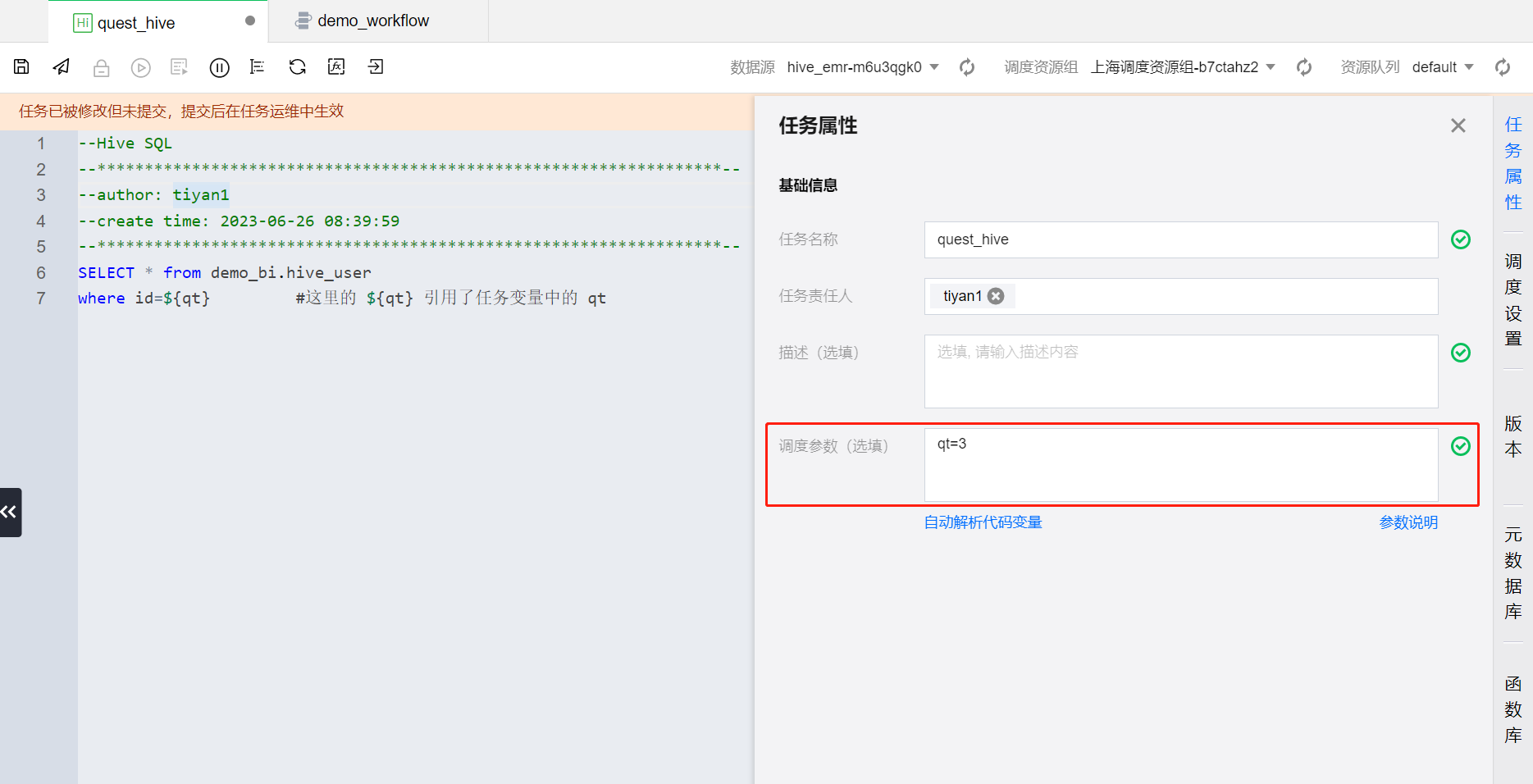
1. 在 quest_hive 计算任务的调度参数中配置以下任务变量。

2. 再在 quest_hive 进行代码开发时应用该变量名,格式为:${变量名}。
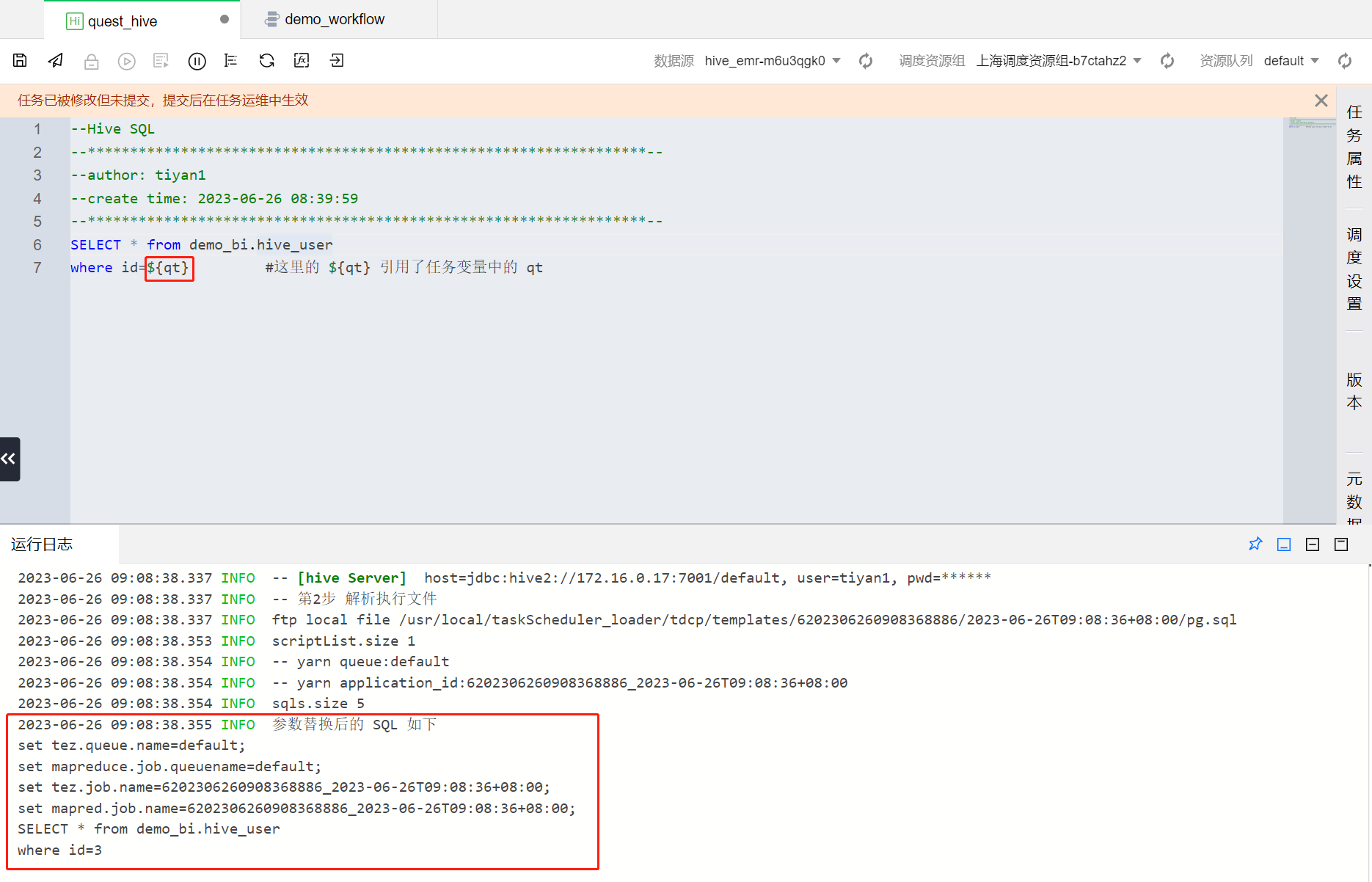
SELECT * from demo_bi.hive_userwhere id=${qt} #这里的 ${qt} 引用了任务变量中的 qt
3. 从图中可以看到计算任务中引用了任务变量 qt 后,相应代码在运行时进行了参数替换。
4. 另外,在任务变量配置时提供详细的参数说明,能够帮助用户快速理解并使用功能;在任务变量配置时单击自动解析代码变量功能会弹出变量列表,可以检查变量配置是否符合预期。

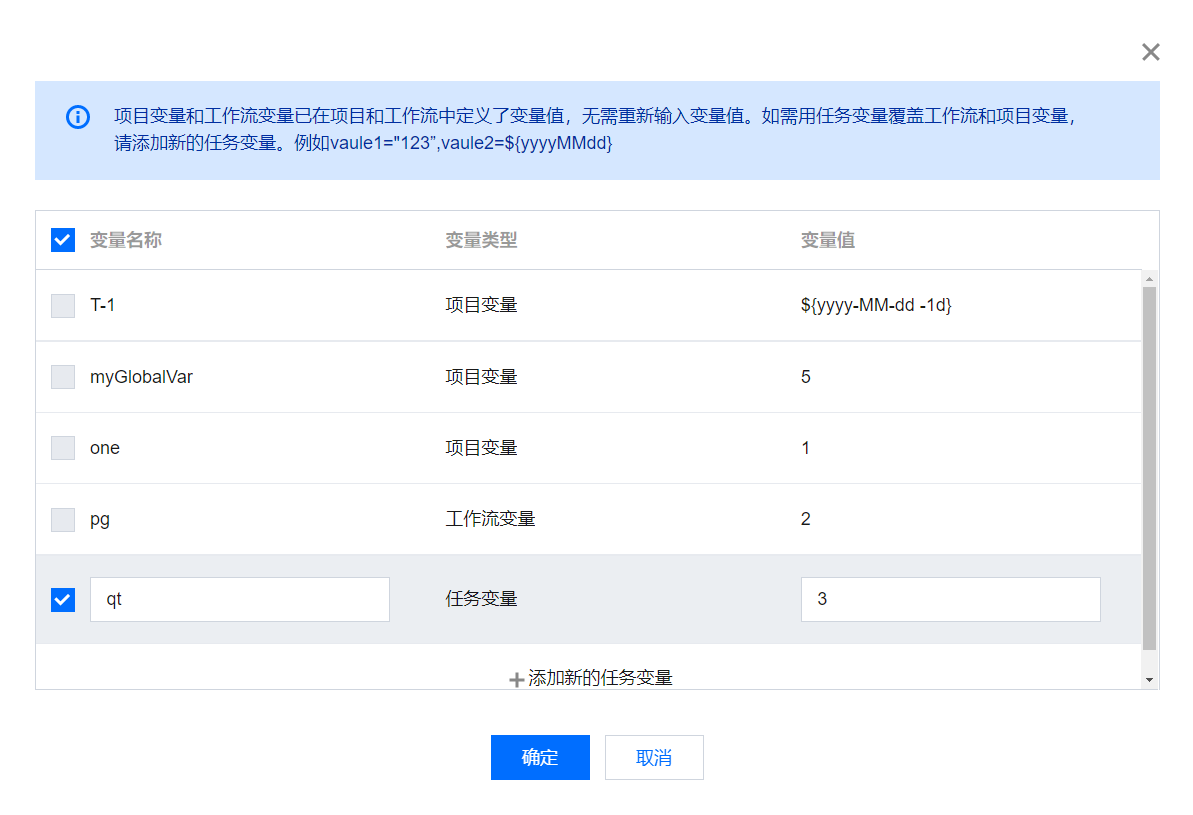
5. 同时可以在变量列表中查看当前任务可以使用的参数变量信息,包括项目变量、工作流变量与任务变量。支持修改当前任务配置的任务变量,以及为当前任务新增任务变量。
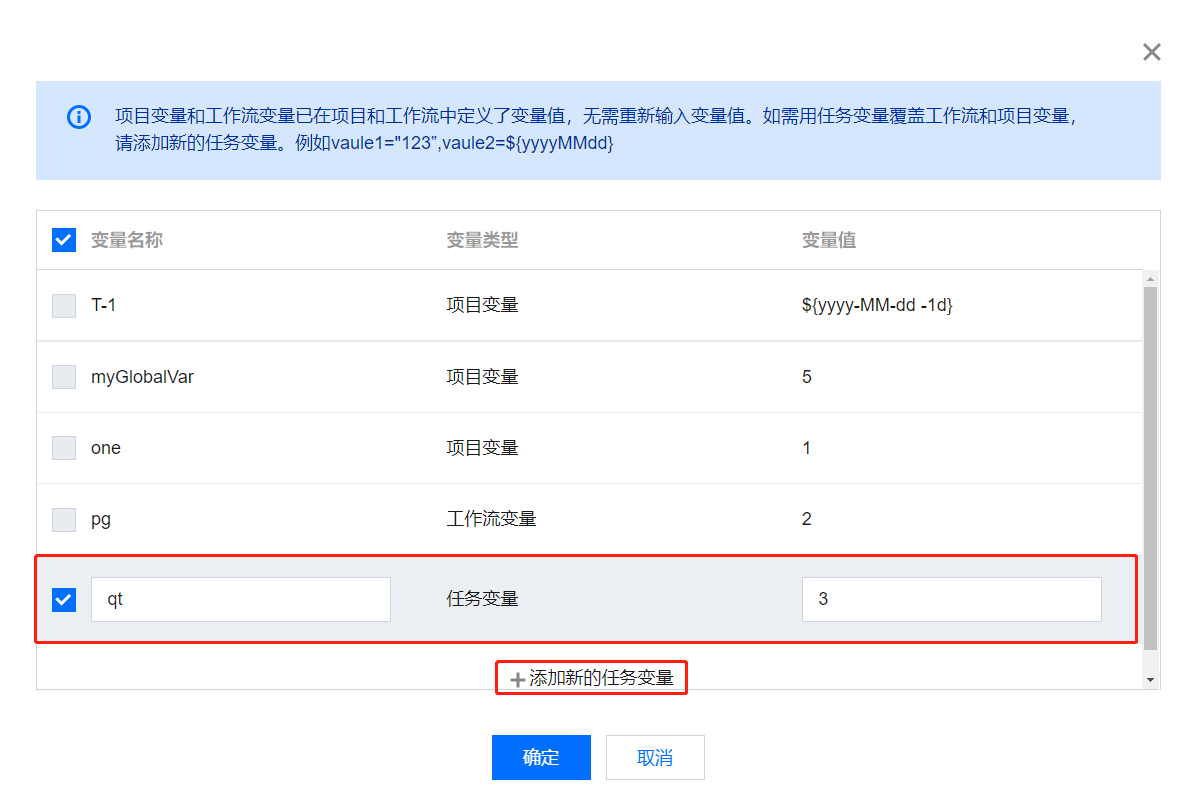
6. 数据工作流中多个任务节点内配置的不同任务变量,可以按照依赖关系提供参数传递能力进行互通。
应用变量
可以通过应用变量的形式来获取项目、工作流以及计算任务信息。在 SQL 任务、YARN 中查看计算任务相关信息。
目前支持的内置应用变量包括:
1. 项目标识:${projectIdent}
2. 工作流名称:${workflowName}
3. 任务名称:${taskName}
4. 任务 ID:${taskId}
5. 负责人(测试运行取当前操作人;周期运行取任务负责人):${taskInCharge}
6. 任务类型:${taskType}
使用场景
在 SQL 中使用获取任务信息。
可以在 SQL 语句中查询应用变量,获取当前项目、工作流等信息。
SQL 示例:
select"${projectIdent}" as projectIdent,"${workflowName}" as workflowName,"${taskName}" as taskName,"${taskId}" as taskId,"${taskInCharge}" as taskInCharge,"${taskType}" as taskType,user_idfromwedata_demo_db.user_infolimit10;
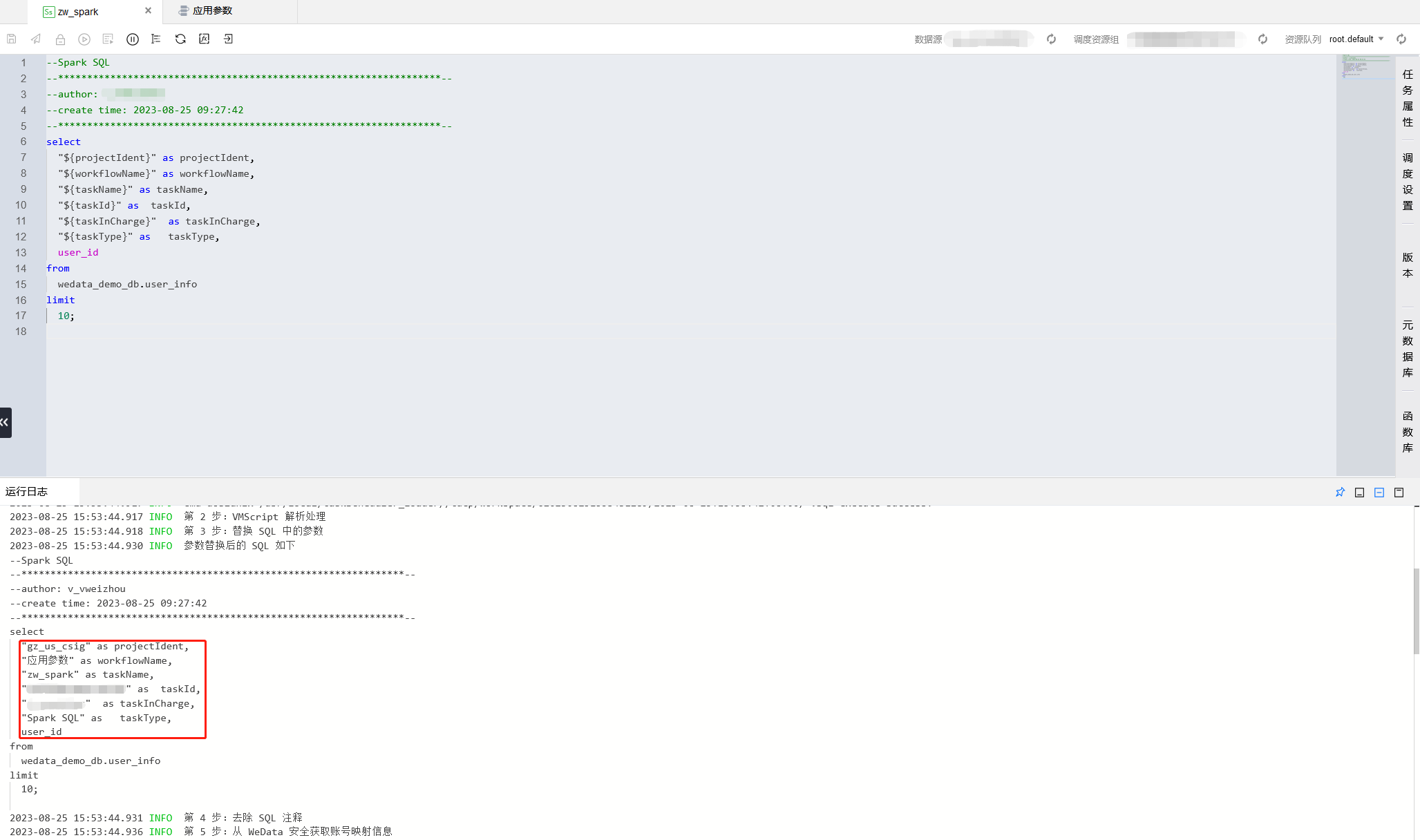
在 YARN 上指定任务名称。
在 SparkSQL、PySpark、Spark 任务类型中使用 --name + 变量来指定 YARN 上的任务名称。
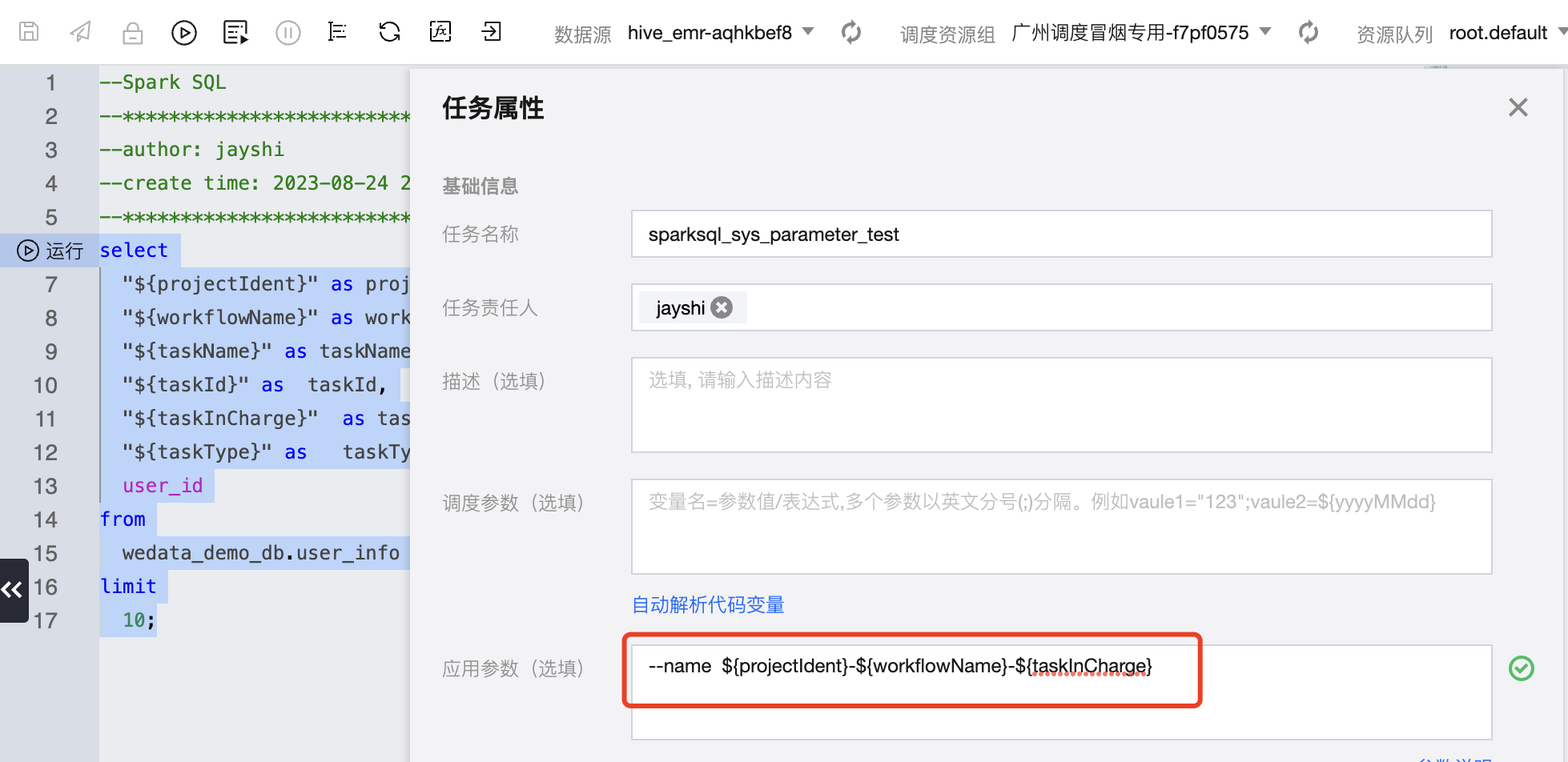
参数示例:
--name ${projectIdent}-${workflowName}-${taskInCharge}
注意:
在 SparkSQL 连接 kyuubi 数据源的时候,目前参数名称需要使用 spark.app.name 来指定。
spark.app.name=${projectIdent}-${workflowName}-${taskInCharge}
在 YARN 上的最终效果:

其他说明
目前如果之前提交过了 kyuubi 作业,后面提交的 kyuubi 作业可能会复用之前 kyuubi 的 YARN 的 application id,造成 application name 重名。该问题研发正在排查和解决中。
文档反馈