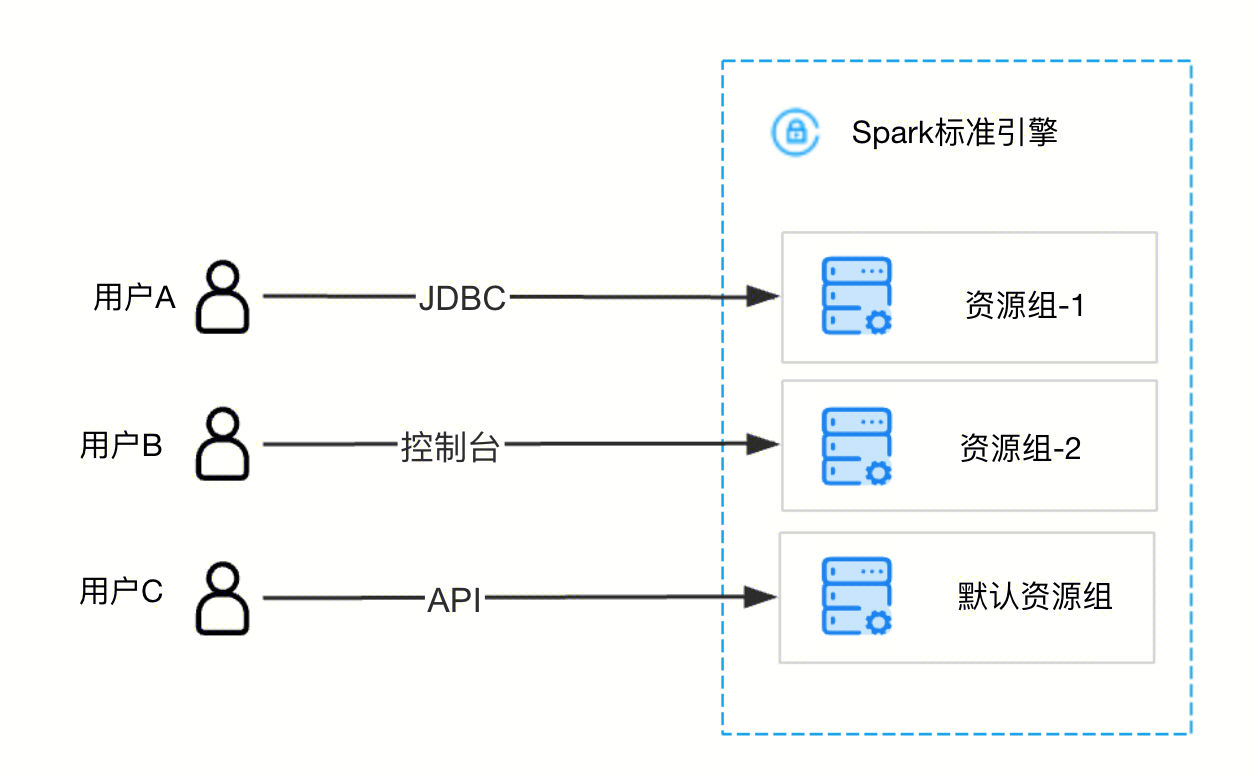
资源组是对 Spark 标准引擎计算资源的二级队列划分,资源组隶属于父级标准引擎且同一引擎下的资源组彼此资源共享。DLC Spark 标准引擎的计算单元(CU)可按需被划分到多个资源组中,并设置每个资源组可使用 CU 数量的最小值和上限、启停策略、并发数和动静态参数等,从而满足多租户、多任务等复杂场景下的计算资源隔离与工作负载的高效管理。
例如,您可为一个 Spark 标准引擎创建报表资源组、数仓资源组、历史补录资源组,设定每个资源组的计算单元 CU 上下限,并在业务中将相关报表、数仓等SQL 任务或作业提交到对应的资源组中,实现不同类别任务间的资源隔离,避免个别大查询将资源长期抢占。
功能特性
资源组隔离
使用资源组可实现对 Spark 标准引擎的资源隔离。您可对不同用户、不同查询分配相应的资源组,从而起到资源隔离的作用,避免单个用户或大查询独占大部分计算引擎资源。
资源组弹性
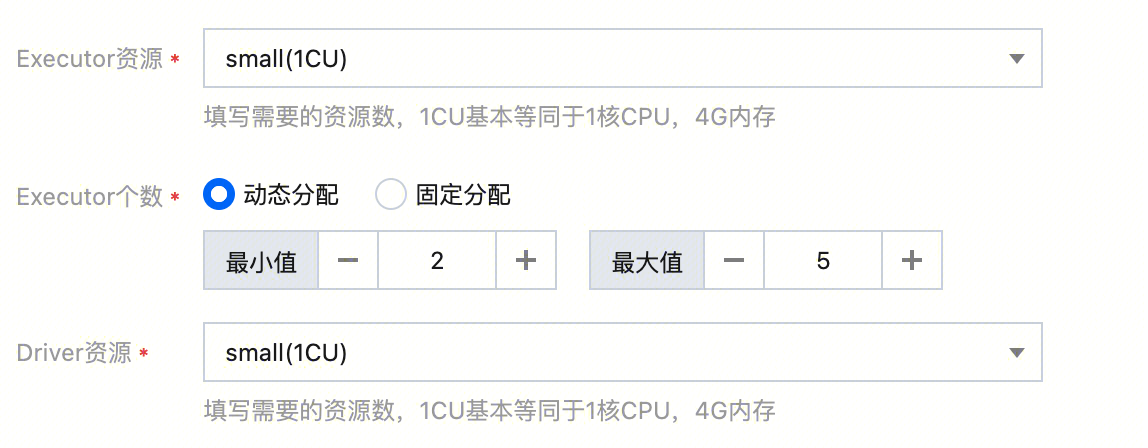
配置资源组 Executor 个数为动态分配,资源组会根据负载动态调整 SQL 任务或作业占用的资源,有效提高资源利用率。
动态分配配置如下图所示:
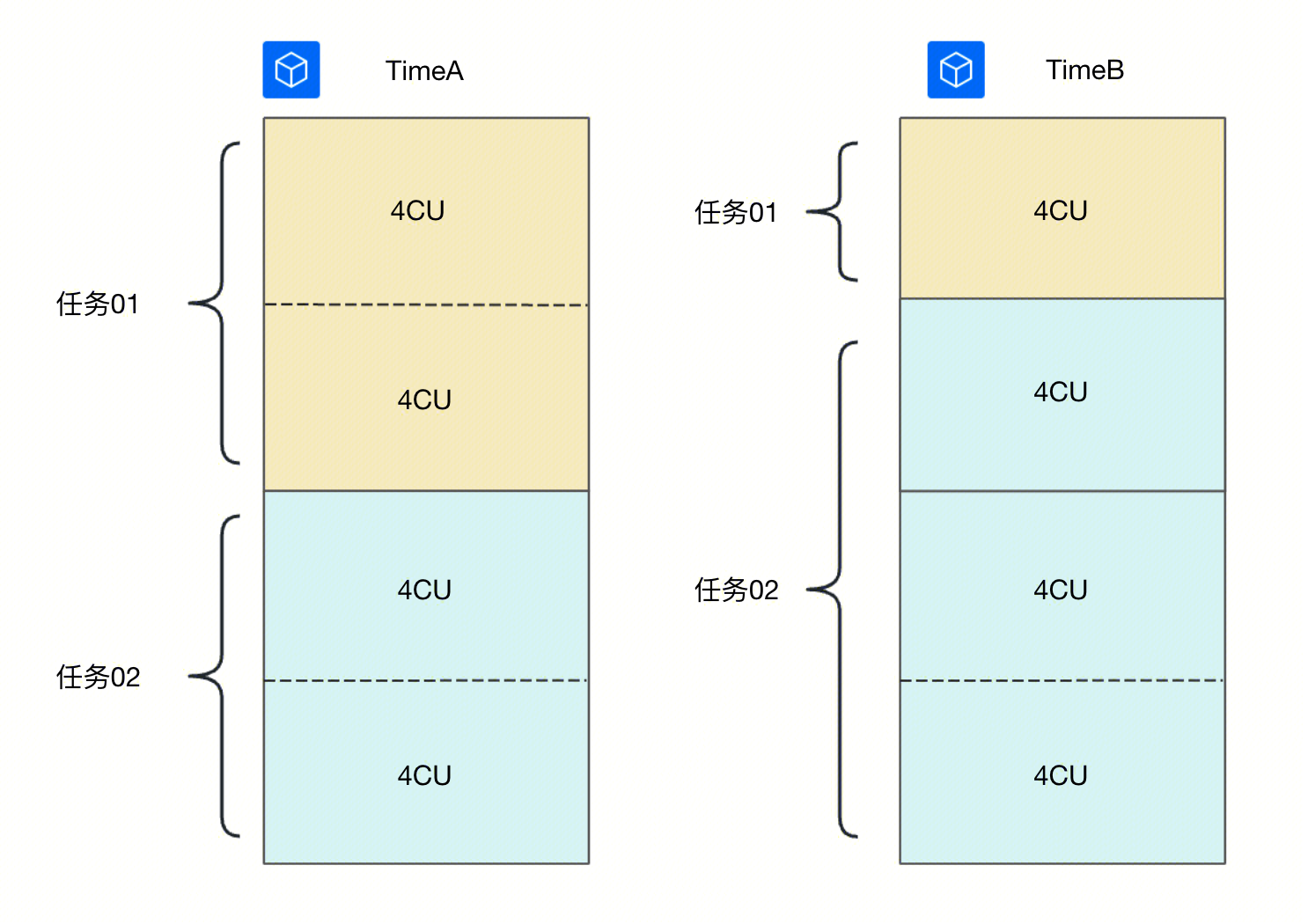
任务01和任务02均设置动态分配,在 TimeA 各占8CU资源量执行,执行到 TimeB 任务01只需要4CU,释放4CU空闲资源给任务02使用,提高了整体资源利用率。如下图所示:
资源组类型
当前 DLC 支持三种类型资源组:仅 SQL 分析资源组、作业资源组和机器学习资源组,并支持在购买标准引擎时默认创建“仅SQL分析”和“作业”类型资源组,支持用户自主创建“仅SQL分析”和“机器学习”类型资源组。以下分别介绍三种资源组的使用场景及特性:
仅 SQL分析资源组:可在数据探索等模块中设置并使用,支持 SQL 查询分析场景。
作业资源组:用于数据作业场景。在创建数据作业时选择引擎则可默认使用该引擎的作业资源组,该作业的资源配置可在创建数据作业时设置。
机器学习资源组:用于使用 Python、ML 机器学习框架、PySpark 的方式进行AI模型训练的场景。
快速配置
资源组资源提供了快速配置选项,用户可便捷地设定资源组总规格(单位:CU个数),后台根据策略自动分配资源。
具体策略如下:
1. 默认开启动态分配。
2. 总规格[4,8):driver 和 executor 使用2CU。
3. 总规格[8,64):driver 和 executor 使用4CU。
4. 总规格[64,∞):driver 和 executor 使用8CU。
资源组监控
资源组监控为用户提供全面的任务与资源使用情况洞察,帮助优化资源分配与调度效率。
资源组概览
1. 资源上限:若资源组未开启动态分配,则为资源组固定资源。若资源组开启动态分配,则为资源组设定的 Max 资源。
2. 已占用资源:实时获取对应资源组拉起 Pod 所占用的资源。
3. 剩余可用资源:用户在当前资源组可用资源,即资源上限 - 已占用资源。
资源组监控详细指标
任务指标(Task)
统计不同状态下的任务数量,包括取消、失败、初始化、运行中、排队和成功状态。
任务时长指标:平均初始化时长、最大初始化时长、平均排队时长及最大排队时长,帮助分析任务启动与调度效率。
资源聚合指标
资源组拉起的 Executor Core 总数,反映资源组申请的计算资源规模。
资源组活跃使用的 Executor Core 总数,展示当前实际使用的计算资源量。
计算单元(CU)指标
资源组 CU 占用量,量化资源组消耗的计算单元资源。
CU 使用率,反映资源组计算资源的利用效率。
注意:
机器学习资源组的监控暂时仅支持计算单元(CU)指标。
使用限制
资源组名称全局唯一,名称推荐使用全英文名称。
相关术语
|
默认资源组 (系统默认创建) | 仅SQL分析资源组:引擎创建时便存在,以 default-rg-xxx 命名。 该默认资源组,初始状态为挂起,设置自动启动和自动挂起。 该默认资源组支持修改资源配置。 该默认资源组支持设置启停策略、并发数和动静态参数。 该默认资源组支持依赖包管理功能。 该默认资源组不可以删除。 作业资源组:引擎创建时便存在,不支持挂起、启动和重启等操作,以 default-job-rg-xxx 命名。 该默认资源组,初始状态为就绪,不可设置自动启动, 自动挂起。 该默认资源组不支持修改资源配置,默认为引擎资源上限。 该默认资源组不支持设置启停策略和并发数,支持设置动静态参数。 该默认资源组支持依赖包管理功能。 该默认资源组不可以删除 |
自定义资源组 (用户手动创建) | 自定义资源组支持修改资源配置。 自定义资源组支持设置启停策略、并发数和动静态参数。 自定义资源组支持删除。 作业资源组不支持自定义及自定义资源组的相关操作。 |