跨可用区服务高可用
Download
聚焦模式
字号
机架感知概述
Hadoop 集群机架感知是指 Hadoop 分布式计算框架中的节点会根据网络拓扑结构进行组织,并且在任务调度和数据存储时将优先发生在同一机架内的节点之间,以提高集群性能和可靠性的技术。
它是由 HDFS 和 YARN 两个组件来支持的。HDFS 通过将数据块的副本分布在不同的机架上,实现数据的高可靠性和高可用性。YARN 则通过将任务分配到距离更近的节点或容器上,提高任务执行的效率和性能。
而 Hadoop 无法自动发现节点的网络拓扑结构,所以提供了以下方式帮助其感知:
自定义 Java 类实现 DNSToSwitchMapping 的接口方法,并在 core-site.xml 配置文件中由 net.topology.node.switch.mapping.impl 参数指定类名。
基于脚本进行拓扑映射,并在 core-site.xml 配置文件中使用 net.topology.script.file.name 参数指定。
下面提供了基于脚本配置机架感知策略的示例,基本方法是映射可用区子网到机架信息。
说明
基于脚本配置机架感知策略
1. 准备一个跨可用区的 EMR 集群,登录 EMR 控制台,单击集群 ID/名称进入集群详情页,在实例信息 > 部署信息中确认集群所在的 VPC 网络信息和不同可用区对应的子网。
然后在私有网络 > 子网中获取子网的 CIDR 与可用区的映射信息。
注意
VPC 名称和子网名称均可能存在重复情况,此时需进入集群资源下的实例信息进一步确认。
2. 根据子网 CIDR 与可用区的映射信息,准备机架感知脚本 RackAware.py。
说明:
本为使用 /usr/bin/python 路径下的 python2 版本为示例,其中 #CIDR# 需替换为子网 CIDR。
#!/usr/bin/pythonimport sysimport IPyimport reDEFAULT_RACK="/default-rack"cidrToRack = {' #CIDR#' : 'rack-1',' #CIDR#' : 'rack-2',' #CIDR#' : 'rack-3'}for name in sys.argv[1:]:rack = DEFAULT_RACKips = re.findall(r'[0-9]+(?:\\.[0-9]+){3}', name)if len(name) > 0 and len(ips) > 0:ip = ips[0]for cidr in cidrToRack.keys():if ip in IPy.IP(cidr):rack = cidrToRack[cidr]breakprint "/{0}".format(rack)
3. 集群服务> HDFS > 配置管理中,新增 RackAware.py 文件,并在 NameNode 节 点core-site.xml 文件增加配置项
net.topology.script.file.name=/usr/local/service/hadoop/etc/hadoop/RackAware.py。4. 控制台重启 NameNode和ResourceManager。
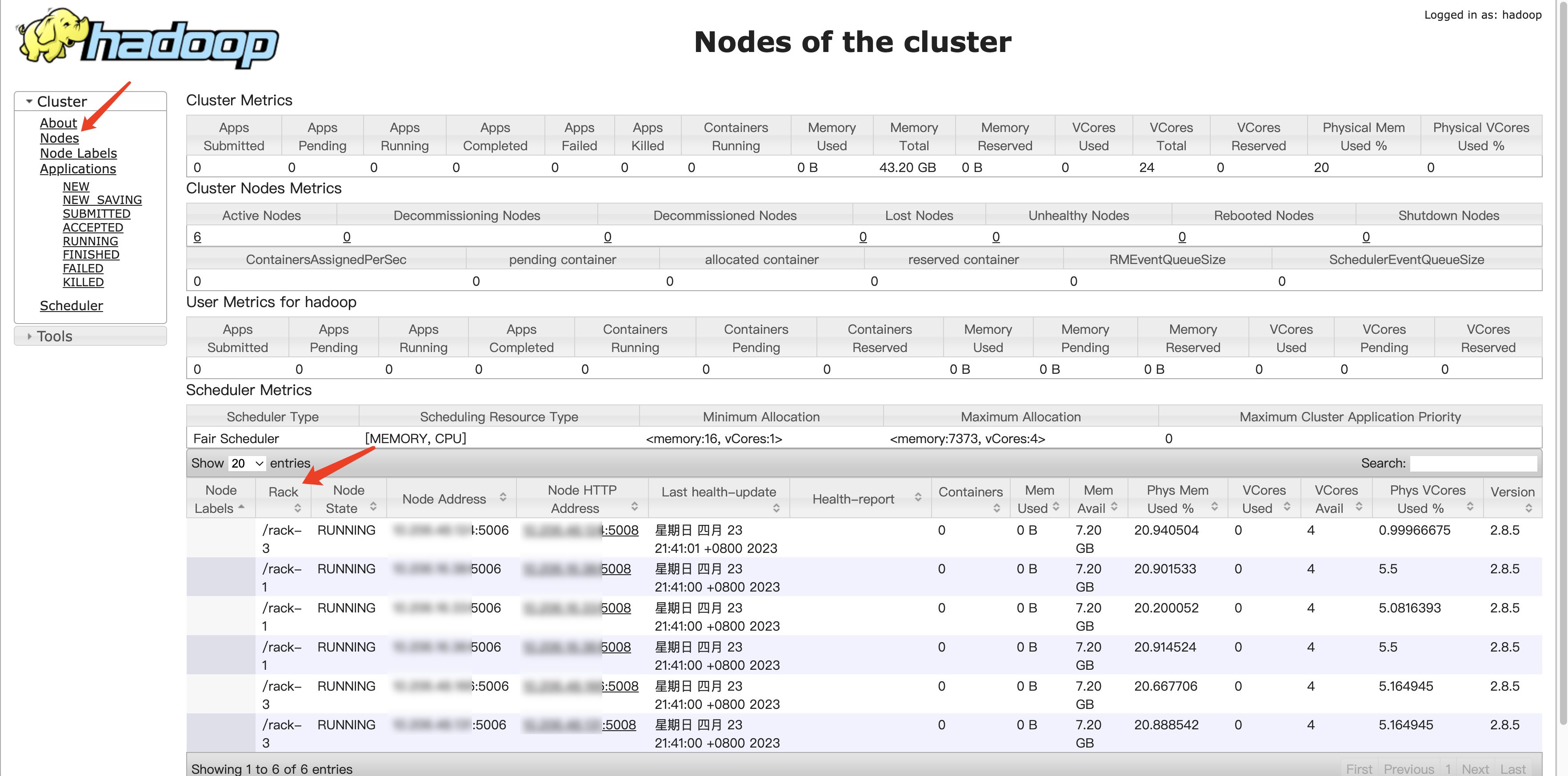
查看集群的机架信息
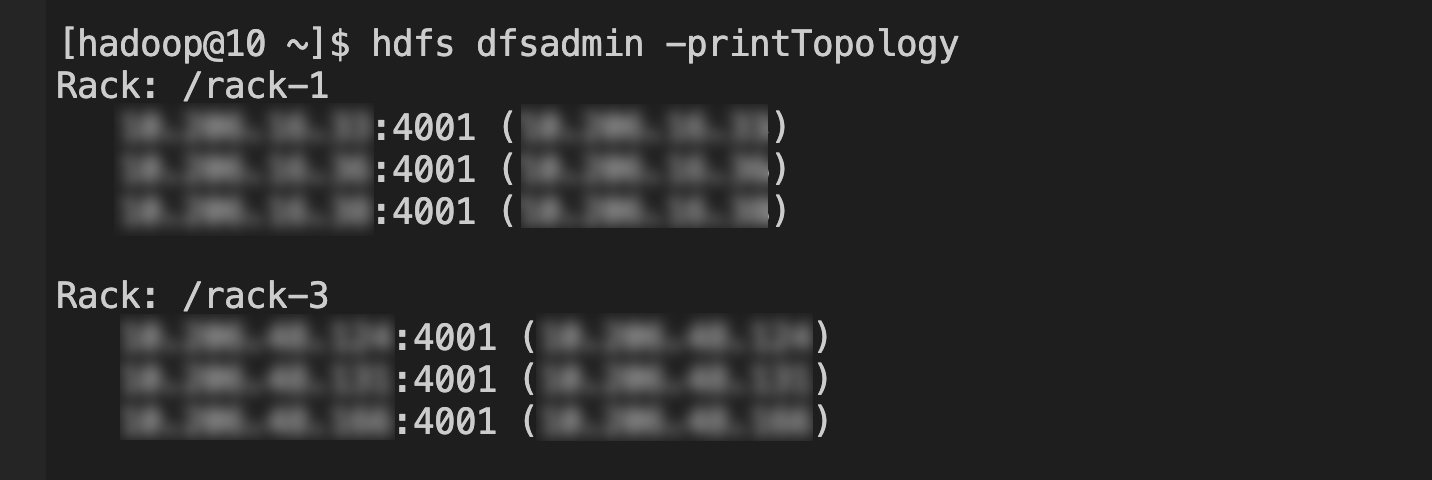
HDFS 服务:登录 NameNode 节点,hadoop 用户执行 hdfs dfsadmin -printTopology,如下:
文档反馈