Kyuubi 实践教程
Download
聚焦模式
字号
Beeline 连接 kyuubi
登录 EMR 集群的 Master 节点,切换到 Hadoop 用户并且进入 kyuubi 目录:
[root@172 ~]# su hadoop[hadoop@172 root]$ cd /usr/local/service/kyuubi
连接 kyuubi:
[hadoop@10kyuubi]$ bin/beeline -u "jdbc:hive2://${zkserverip1}:${zkport},${zkserverip2}:${zkport},${zkserverip3}:${zkport}/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi" -n hadoop
或者
[hadoop@10kyuubi]$ bin/beeline -u "jdbc:hive2://${kyuubiserverip}:${kyuubiserverport}" -n hadoop
${zkserverip}:${zkport} 见 kyuubi-defaults.conf 的 kyuubi.ha.zookeeper.quorum 配置。
${kyuubiserverport} 见 kyuubi-defaults.conf 的 kyuubi.frontend.bind.port 配置。新建数据库并查看
在新建的数据库中新建一个表,并进行查看:
0: jdbc:hive2://ip:port> create database sparksql;+---------+| Result |+---------++---------+No rows selected (0.326 seconds)
向表中插入两行数据并查看:
0: jdbc:hive2://ip:port> use sparksql;+---------+| Result |+---------++---------+No rows selected (0.077 seconds)0: jdbc:hive2://ip:port> create table sparksql_test(a int,b string);+---------+| Result |+---------++---------+No rows selected (0.402 seconds)0: jdbc:hive2://ip:port> show tables;+-----------+----------------+--------------+| database | tableName | isTemporary |+-----------+----------------+--------------+| sparksql | sparksql_test | false |+-----------+----------------+--------------+1 row selected (0.108 seconds)
Hue 连接 kyuubi
前提条件
针对在现有集群里后安装 kyuubi 场景,若想在 hue 上使用 kyuubi,需要做如下操作:
1. 进入 HDFS 的配置管理,core-site.xml 新增配置项 hadoop.proxyuser.hue.groups 值设为“ * ”和 hadoop.proxyuser.hue.hosts值设为“ * ” 。
2. 重启 kyuubi 服务和 hue 服务。
3. 访问 Hue 控 制台,详情请参见 登录 Hue 控制台。
Kyuubi 查询
1. 在 Hue 控制台上方,选择 Query > Editor > SparkSql_Kyuubi。

2. 在语句输入框中输入要执行语句,然后单击执行,执行语句。
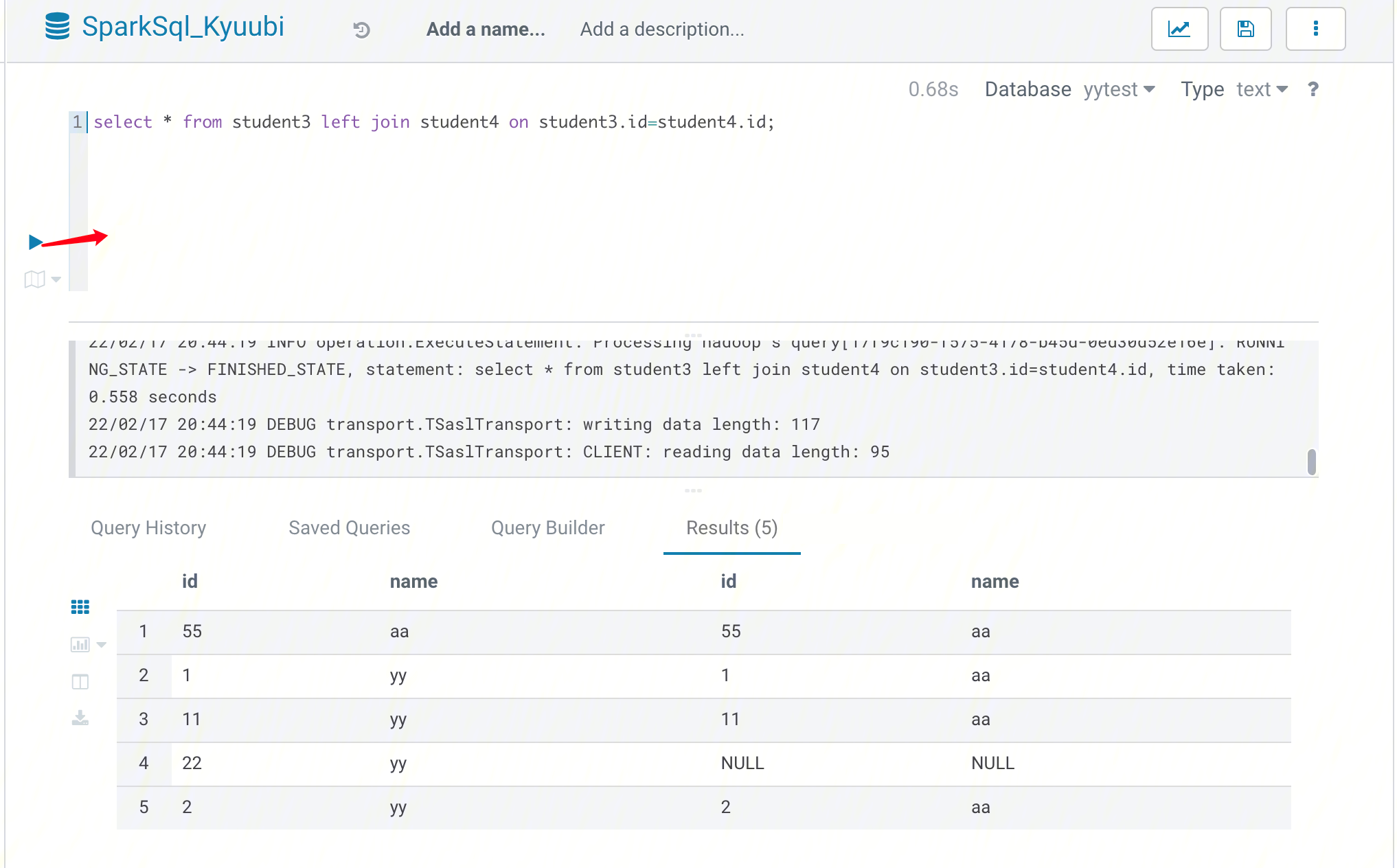
通过 Java 连接 Kyuubi
KyuubiServer 中集成了 Thrift 服务。Thrift 是 Facebook 开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发。Kyuubi 就是基于 Thrift 的,所以能让不同的语言如 Java、Python 来调用 Kyuubi 的接口。对于 Java,Kyuubi 复用了hive jdbc 驱动,用户可以使用 Java 代码来连接 Kyuubi 并进行一系列操作。本节将演示如何使用 Java 代码来连接 Kyuubi。
1. 开发准备。
确认您已经开通了腾讯云,并且创建了一个 EMR 集群。在创建 EMR 集群的时候需要在软件配置界面选择 Kyuubi 及 Spark 组件。
Kyuubi 等相关软件安装在路径 EMR 云服务器的/usr/local/service/路径下。
2. 使用 Maven 来创建您的工程。
推荐使用 Maven 来管理您的工程。Maven 是一个项目管理工具,能够帮助您方便的管理项目的依赖信息,即它可以通过 pom.xml 文件的配置获取 jar 包,而不用去手动添加。首先在本地下载并安装 Maven,配置好 Maven 的环境变量,如果您使用 IDE,请在 IDE 中设置好 Maven 相关配置。
在本地 shell 下进入要新建工程的目录,例如:D://mavenWorkplace 中,输入如下命令新建一个 Maven 工程:
mvn archetype:generate -DgroupId=$yourgroupID -DartifactId=$yourartifactID -DarchetypeArtifactId=maven-archetype-quickstart
其中 $yourgroupID 即为您的包名;$yourartifactID 为您的项目名称;maven-archetype-quickstart 表示创建一个 Maven Java 项目。工程创建过程中需要下载一些文件,请保持网络通畅。创建成功后,在 D://mavenWorkplace 目录下就会生成一个名为 $yourartifactID 的工程文件夹。其中的文件结构如下所示:
simple---pom.xml 核心配置,项目根下---src---main---java Java 源码目录---resources Java 配置文件目录---test---java 测试源码目录---resources 测试配置目录
其中我们主要关心 pom.xml 文件和 main 下的 Java 文件夹。pom.xml 文件主要用于依赖和打包配置,Java 文件夹下放置您的源代码。首先在 pom.xml 中添加 Maven 依赖:
<dependencies><dependency><groupId>org.apache.kyuubi</groupId><artifactId>kyuubi-hive-jdbc-shaded</artifactId><version>1.4.1-incubating</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><!-- keep consistent with the build hadoop version --><version>2.8.5</version></dependency></dependencies>
继续在 pom.xml 中添加打包和编译插件:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.8</source><target>1.8</target><encoding>utf-8</encoding></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
在 src>main>Java 下右键新建一个 Java Class,输入您的 Class 名,这里使用 KyuubiJDBCTest.java,在 Class 添加样例代码:
import java.sql.*;public class KyuubiJDBCTest {private static String driverName ="org.apache.kyuubi.jdbc.KyuubiHiveDriver";public static void main(String[] args)throws SQLException {try {Class.forName(driverName);} catch (ClassNotFoundException e) {e.printStackTrace();System.exit(1);}Connection con = DriverManager.getConnection("jdbc:hive2://$kyuubiserverhost:$kyuubiserverport/default", "hadoop", "");Statement stmt = con.createStatement();String tableName = "KyuubiTestByJava";stmt.execute("drop table if exists " + tableName);stmt.execute("create table " + tableName +" (key int, value string)");System.out.println("Create table success!");// show tablesString sql = "show tables '" + tableName + "'";System.out.println("Running: " + sql);ResultSet res = stmt.executeQuery(sql);if (res.next()) {System.out.println(res.getString(1));}// describe tablesql = "describe " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(res.getString(1) + "\\t" + res.getString(2));}sql = "insert into " + tableName + " values (42,\\"hello\\"),(48,\\"world\\")";stmt.execute(sql);sql = "select * from " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(String.valueOf(res.getInt(1)) + "\\t"+ res.getString(2));}sql = "select count(1) from " + tableName;System.out.println("Running: " + sql);res = stmt.executeQuery(sql);while (res.next()) {System.out.println(res.getString(1));}}}
注意
将程序中的参数 $kyuubiserverhost 和 $kyuubiserverport 分别修改为您查到的 KyuubiServer 的 ip 和端口号的值。
如果您的 Maven 配置正确并且成功的导入了依赖包,那么整个工程即可直接编译。在本地 shell 下进入工程目录,执行下面的命令对整个工程进行打包。
mvn package
3. 上传并运行程序。
首先需要把压缩好的 jar 包上传到 EMR 集群中,使用 scp 或者 sftp 工具来进行上传。在本地 shell 下运行:
scp $localfile root@公网IP地址:/usr/local/service/kyuubi
一定要上传具有依赖的 jar 包。登录 EMR 集群切换到 Hadoop 用户并且进入目录 /usr/local/service/kyuubi 。接下来可以执行程序:
[hadoop@172 kyuubi]$ yarn jar $package.jar KyuubiJDBCTest
其中 $package.jar 为您的 jar 包的路径 + 名字,KyuubiJDBCTest 为之前的 Java Class 的名字。运行结果如下:
Create table success!Running: show tables 'KyuubiTestByJava'defaultRunning: describe KyuubiTestByJavakey intvalue stringRunning: select * from KyuubiTestByJava42 hello48 worldRunning: select count(1) from KyuubiTestByJava2
文档反馈