产品动态
产品公告
安全公告
${HADOOP_HOME}/etc/hadoop/yarn-site.xml 中设置:<property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value></property>
${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml 中设置 yarn.scheduler.capacity.root 是 Capacity Scheduler 预定义的根队列,其他队列均为根队列的子队列。所有队列以树的形式组织。yarn.scheduler.capacity.<queue-path>.queues 用于设置 queue-path 路径下的子队列,使用逗号分隔。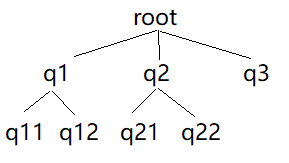
<property><name>yarn.scheduler.capacity.root.queues</name><value>q1,q2,q3</value></property><property><name>yarn.scheduler.capacity.root.q1.queues</name><value>q11,q12</value></property><property><name>yarn.scheduler.capacity.root.q2.queues</name><value>q21,q22</value></property>
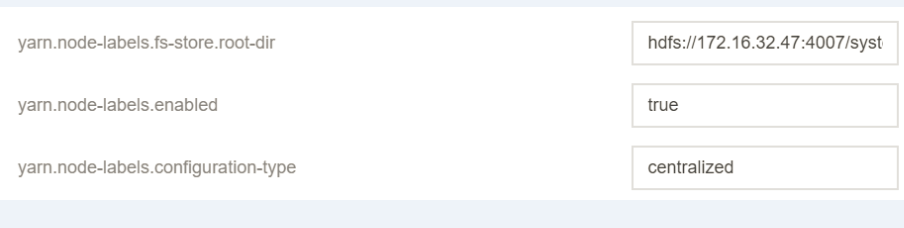
conf/yarn-site.xml中设置。<property><name>yarn.node-labels.fs-store.root-dir</name><value>hdfs://namenode:port/path-to-store/node-labels/</value></property><property><name>yarn.node-labels.enabled</name><value>true</value></property><property><name>yarn.node-labels.configuration-type</name><value>centralized or delegated-centralized or distributed</value></property>
yarn.node-labels.fs-store.root-dir,且 ResourceManager 有权访问。file://home/yarn/node-label 等路径。但是为了保证集群的高可用,避免 RM 宕机而丢失标签信息,建议将标签信息保存在 HDFS 上。yarn.node-labels.configuration-type 配置项。etc/hadoop/capacity-scheduler.xml中设置。配置项 | 描述 |
yarn.scheduler.capacity. <queue-path>.capacity | 设置队列可以访问属于 DEFAULT 分区的节点的百分比。每个 parent 队列下直接子队列的 DEFAULT 容量总和必须等于100。 |
yarn.scheduler.capacity. <queue-path>.accessible-node-labels | 设置队列可以访问的特定标签列表,用逗号分隔,如“HBASE,STORM”意味着队列可以访问标签 HBASE 和 STORM。所有队列都可以在没有标签的情况下访问节点,如果不指定此字段,则将从其父字段继承。如果用户想限制队列仅访问没有标签的节点,该字段只需留空即可。 |
yarn.scheduler.capacity. <queue-path>.accessible-node-labels.<label>.capacity | 设置队列可以访问属于 <label>分区的节点百分比。每个 parent 队列下直接子队列的<label>容量总和必须等于100,默认为0。 |
yarn.scheduler.capacity. <queue-path>.accessible-node-labels.<label>.maximum-capacity | 与 Capacity Scheduler 配置项 yarn.scheduler.capacity. <queue-path>.maximum-capacity 类似,它指定了<queue-path>在<label>分区的最大容量,默认为100。 |
yarn.scheduler.capacity. <queue-path>.default-node-label-expression | 当资源请求未指定节点标签时,应用将被提交到该值对应的分区。默认情况下,该值为空,即应用程序将被分配没有标签的节点上的容器。 |
yarn-site.xml中相关参数,保存并重启所有 YARN 组件。在角色管理标签页确认 ResourceManager 服务所在节点 IP,之后切换至配置管理标签页修改yarn-site.xml中相关参数,保存并重启所有 YARN 组件。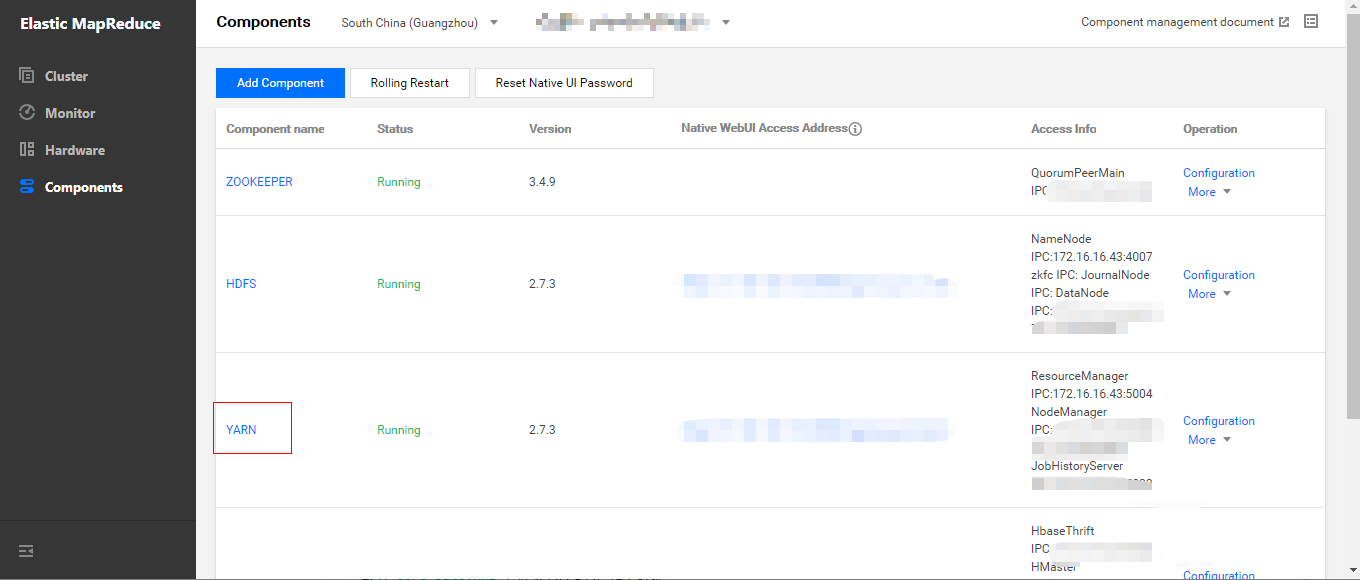
yarn-site.xml的yarn.resourcemanager.scheduler.class参数。
core-site.xml中获取 NN 的 IP 和 Port。

yarn-site.xml中新建配置项后,重启 ResourceManager。
yarn rmadmin -addToClusterNodeLabels命令新增标签。

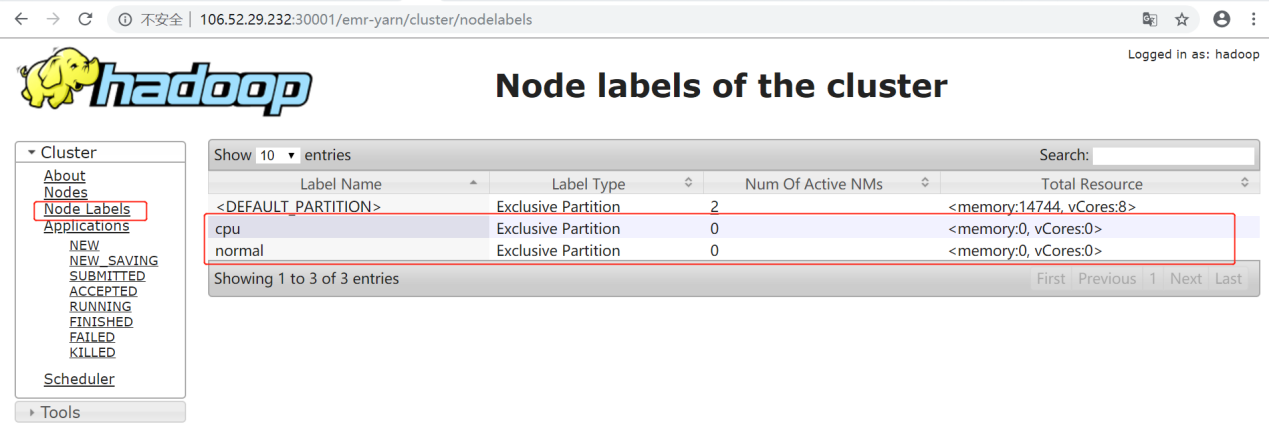
yarn rmadmin -replaceLabelsOnNode命令给节点打标签。

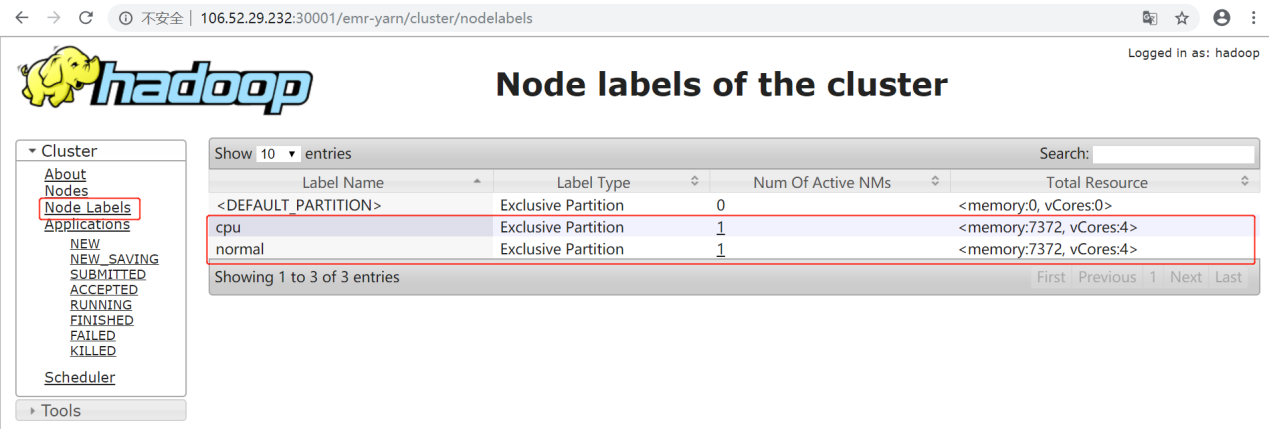
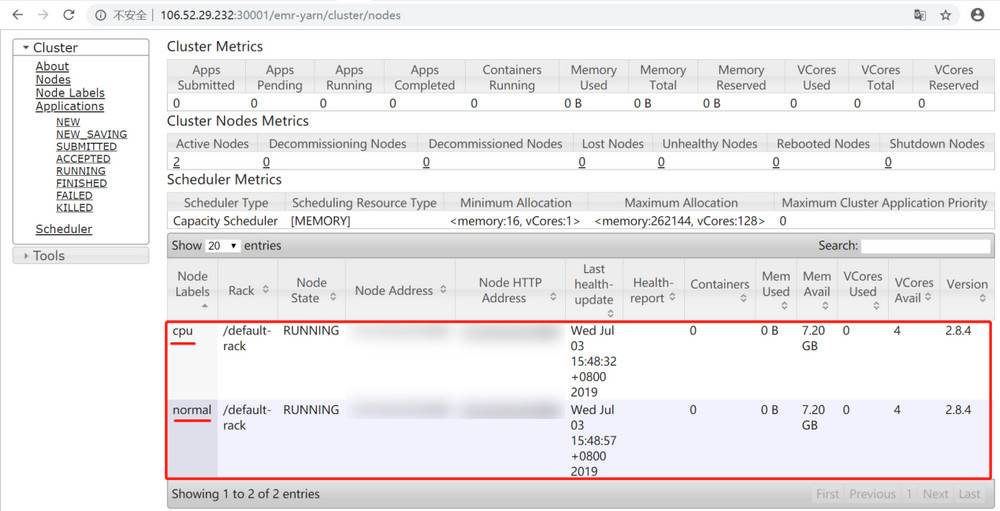
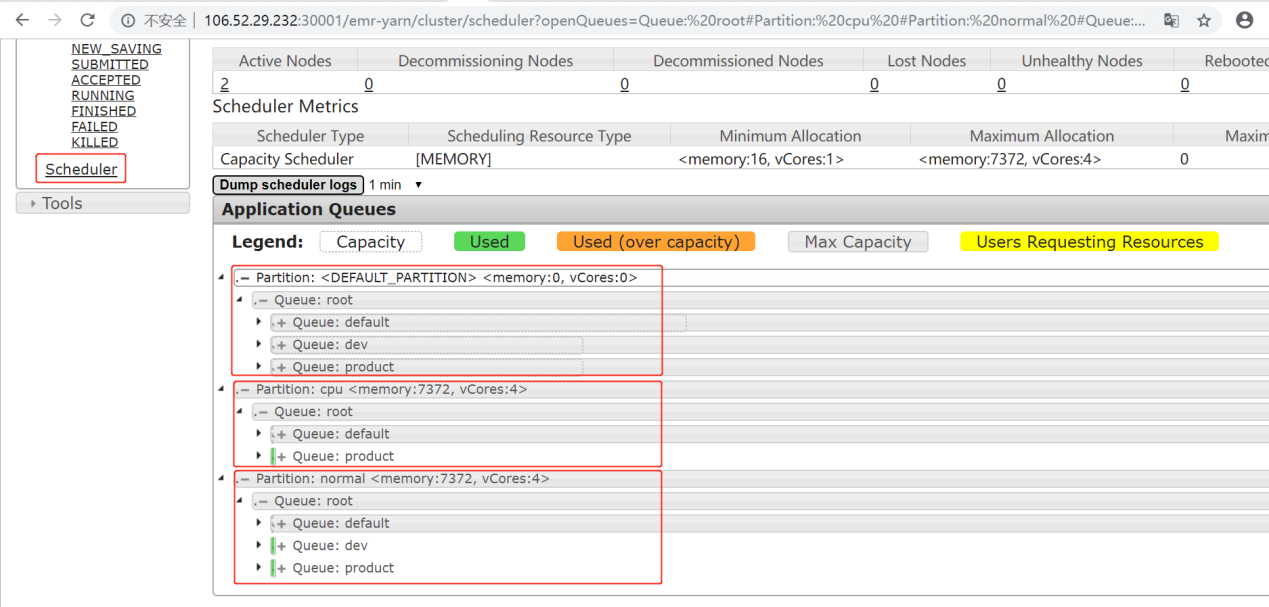
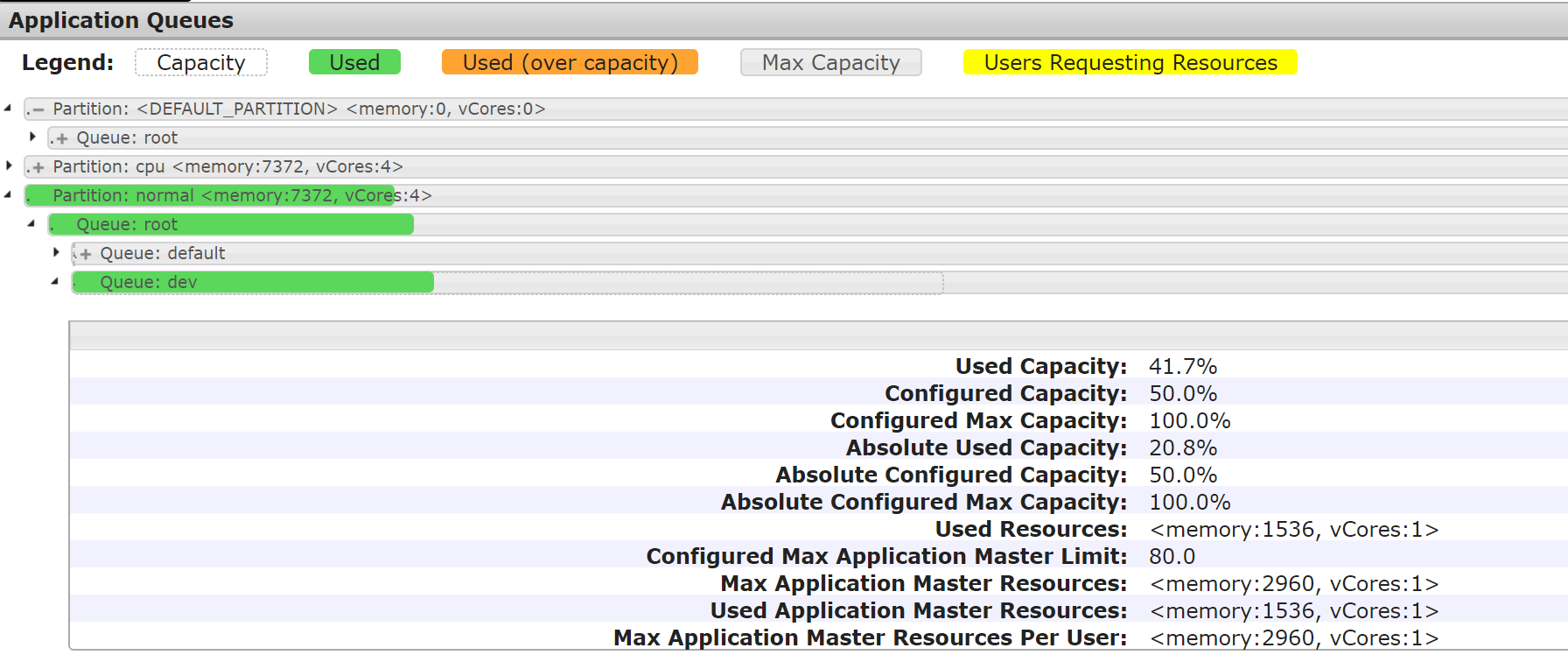
Capacity-Scheduler.xml中的配置项,配置集群队列、队列的资源占比和队列的可访问标签。示例如下:<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>yarn.scheduler.capacity.maximum-am-resource-percent</name><value>0.8</value></property><property><name>yarn.scheduler.capacity.maximum-applications</name><value>1000</value></property><property><name>yarn.scheduler.capacity.root.queues</name><value>default,dev,product</value></property><property><name>yarn.scheduler.capacity.root.default.capacity</name><value>20</value></property><property><name>yarn.scheduler.capacity.root.dev.capacity</name><value>40</value></property><property><name>yarn.scheduler.capacity.root.product.capacity</name><value>40</value></property><property><name>yarn.scheduler.capacity.root.accessible-node-labels.cpu.capacity</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.accessible-node-labels.normal.capacity</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.accessible-node-labels</name><value>*</value></property><property><name>yarn.scheduler.capacity.root.dev.accessible-node-labels.normal.capacity</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.product.accessible-node-labels.cpu.capacity</name><value>100</value></property><property><name>yarn.scheduler.capacity.root.dev.accessible-node-labels</name><value>normal</value></property><property><name>yarn.scheduler.capacity.root.dev.default-node-label-expression</name><value>normal</value></property><property><name>yarn.scheduler.capacity.root.product.accessible-node-labels</name><value>cpu</value></property><property><name>yarn.scheduler.capacity.root.product.default-node-label-expression</name><value>cpu</value></property><property><name>yarn.scheduler.capacity.normal.sharable-partitions</name><value>cpu</value></property><property><name>yarn.scheduler.capacity.normal.require-other-partition-resource</name><value>true</value></property><property><name>yarn.scheduler.capacity.cpu.sharable-partitions</name><value></value></property><property><name>yarn.scheduler.capacity.cpu.require-other-partition-resource</name><value>true</value></property></configuration>
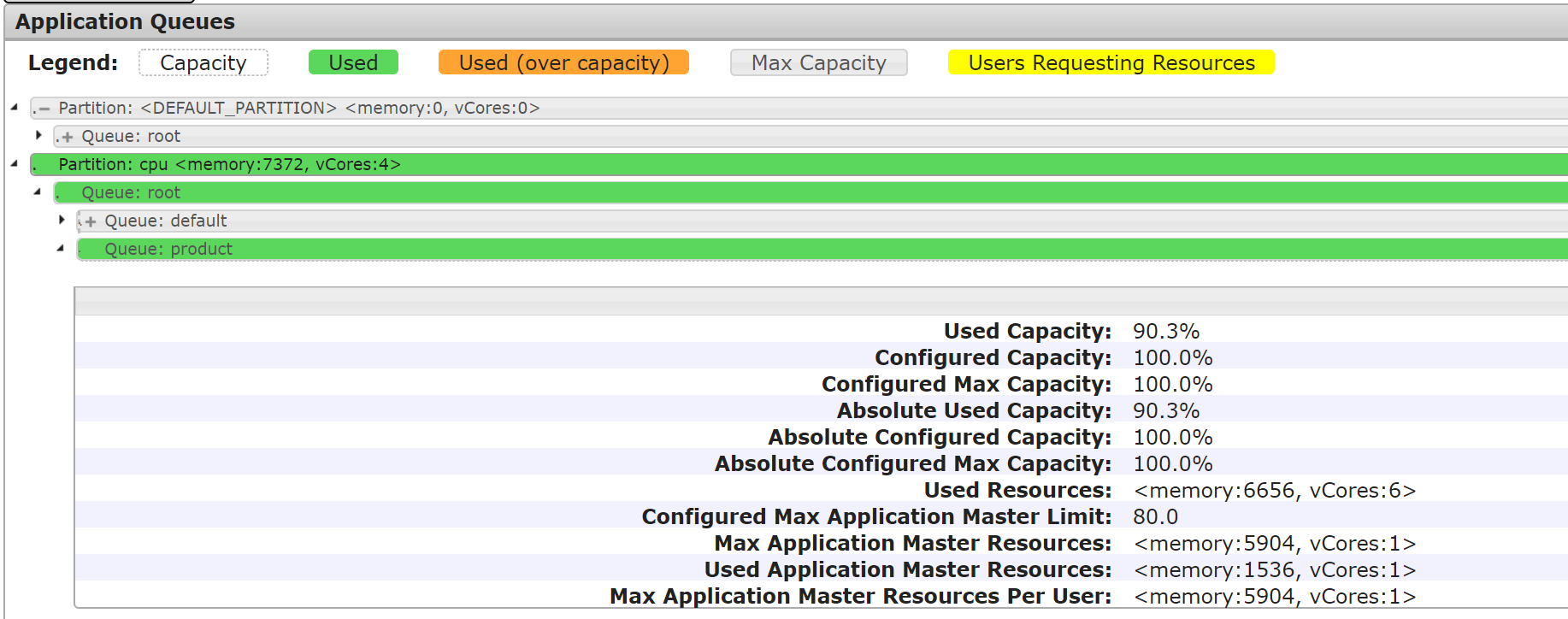
[hadoop@172 hadoop]$ cd /usr/local/service/hadoop[hadoop@172 hadoop]$ yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.8.4-tests.jar sleep -Dmapreduce.job.queuename=product -m 32 -mt 1000
[hadoop@172 hadoop]$ cd /usr/local/service/hadoop[hadoop@172 hadoop]$ yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.8.4-tests.jar sleep -Dmapreduce.job.queuename=dev -m 32 -mt 1000
文档反馈