TKE에서 HPA를 사용하여 비즈니스 오토 스케일링 구현
Download
포커스 모드
폰트 크기
개요
Kubernetes Pod용 HPA(Horizontal Pod Autoscaler)는 CPU 사용량, 메모리 사용량 및 기타 사용자 지정 메트릭을 기반으로 Pod 복제본 수를 자동으로 조정하여 워크로드 서비스의 전체 수준을 사용자 정의 대상 값과 일치시킬 수 있습니다. 이 문서는 TKE의 HPA 기능을 소개하고 이 기능을 사용하여 Pod의 오토 스케일링을 구현하는 방법을 설명합니다.
사용 사례
HPA 기능은 TKE에 유연한 어댑티브 기능을 제공하므로, 사용자 정의 범위 내에서 Pod 복제본 수를 빠르게 늘려 서비스 로드의 급격한 증가에 대처하고 서비스 로드가 감소할 때 스케일 인하여 다른 서비스에 대한 컴퓨팅 리소스를 절약할 수 있습니다. 전체 프로세스는 자동이며 수동 개입이 필요하지 않습니다. 전자상거래 서비스, 온라인 교육, 금융 서비스 등 서비스 변동이 크고 서비스 수가 많으며 스케일링이 빈번한 서비스 시나리오에 적합합니다.
원리 개요
HPA 기능은 Kubernetes API 리소스 및 컨트롤러에 의해 구현됩니다. 리소스는 메트릭을 사용하여 컨트롤러의 동작을 결정하는 반면, 컨트롤러는 Pod 리소스 사용량에 따라 서비스 Pod의 복제본 수를 주기적으로 조정합니다. 워크로드 수준을 사용자 정의 대상 값과 일치시킵니다. 다음 이미지는 스케일링 프로세스를 보여줍니다.
주의사항
Pod에 대한 수평적 오토 스케일링은 DaemonSet 리소스와 같이 스케일링할 수 없는 객체에는 적용되지 않습니다.
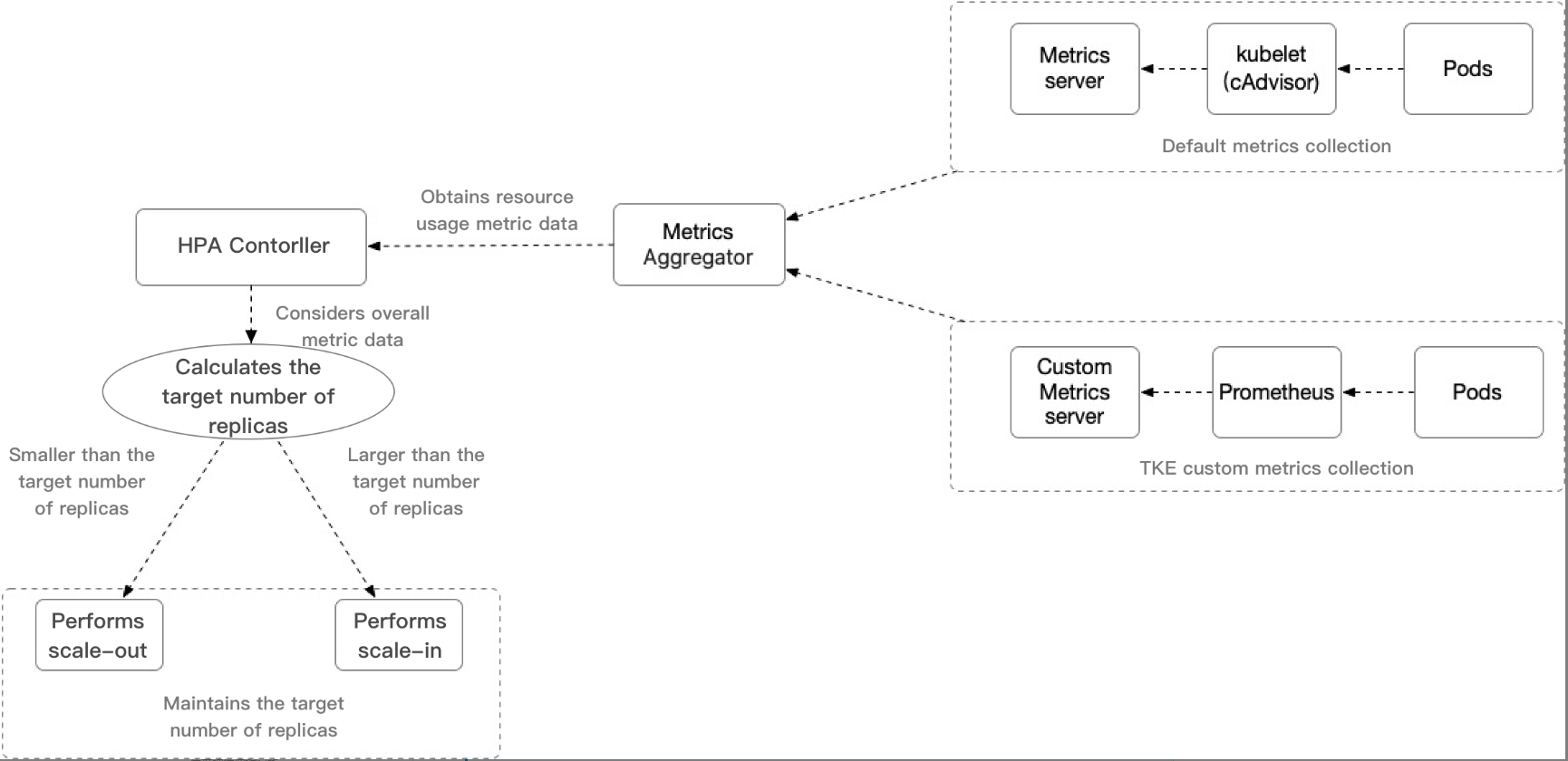
주요 내용:
HPA Controller: HPA 스케일링 로직을 제어하는 제어 컴포넌트입니다.
Metrics Aggregator: 일반적으로 컨트롤러는 일련의 집계 API(
metrics.k8s.io, custom.metrics.k8s.io 및 external.metrics.k8s.io)에서 메트릭 값을 가져옵니다. metrics.k8s.io API는 일반적으로 Metrics 서버에서 제공됩니다. 커뮤니티 에디션은 기본 CPU 및 메모리 메트릭 유형을 제공할 수 있습니다. 커뮤니티 에디션과 비교할 때 TKE에서 사용하는 사용자 지정 Metrics Server 컬렉션은 CPU, 메모리, 디스크, 네트워크 및 GPU 메트릭과 같은 관련 메트릭을 제공하는 광범위한 HPA 메트릭 트리거 유형을 지원합니다. 자세한 내용은 TKE Auto-Scaling 메트릭을 참고하십시오.설명
컨트롤러는 Heapster에서 메트릭을 얻을 수도 있습니다. 그러나 Kubernetes 1.11부터는 컨트롤러가 더 이상 Heapster에서 메트릭을 가져올 수 없습니다.
대상 복제본 수 계산을 위한 HPA 알고리즘: TKE HPA 스케일링 알고리즘은 작동 원리를 참고하십시오. 알고리즘에 대한 자세한 내용은 알고리즘 세부 정보를 참고하십시오.
전제 조건
Tencent Cloud TKE 콘솔에 로그인했습니다.
클러스터를 생성합니다. TKE 클러스터 생성 방법에 대한 자세한 내용은 클러스터 생성을 참고하십시오.
작업 단계
테스트 워크로드 배포
여기서는 Deployment 유형 워크로드를 예로 사용합니다. Web 서비스의 ‘hpa-test’ 워크로드로 설정된 서비스 유형으로 홀수의 복제본을 생성합니다. TKE 콘솔에서 Deployment 유형 워크로드를 생성하는 방법에 대한 자세한 내용은 Deployment 관리를 참고하십시오. 다음 이미지는 이 예시의 생성 결과를 보여줍니다. (이 글의 스크린샷 정보는 콘솔의 실제 인터페이스보다 뒤쳐질 수 있으며 콘솔의 실제 디스플레이가 우선합니다):
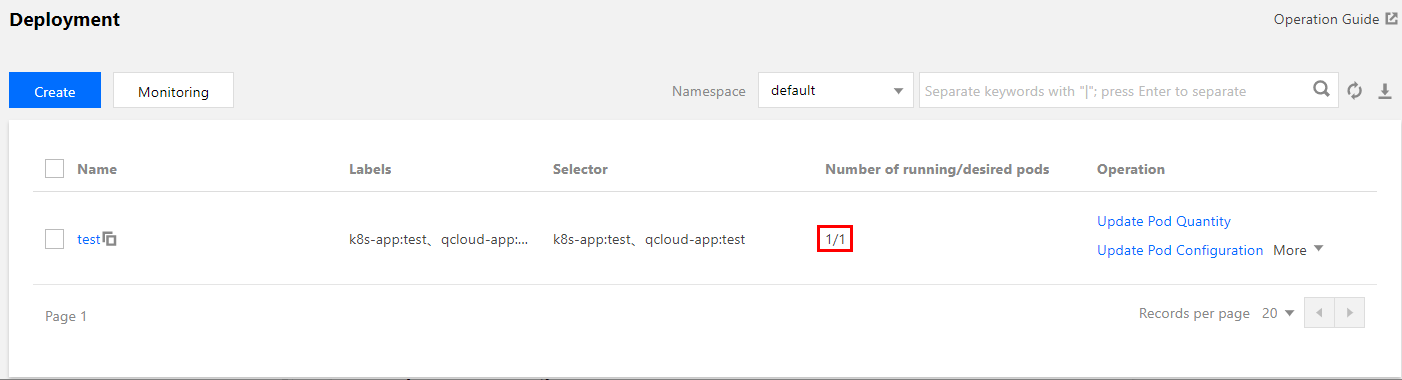
HPA 구성
TKE 콘솔에서 테스트 워크로드를 HPA 구성과 바인딩합니다. HPA 구성을 바인딩하는 방법에 대한 자세한 내용은 HPA 지침을 참고하십시오. 본 문서에서는 아래 이미지와 같이 네트워크 이그레스 대역폭이 0.15Mbps(150Kbps)에 도달하면 스케일 아웃이 트리거되는 정책을 구성하는 예를 들어 설명합니다.
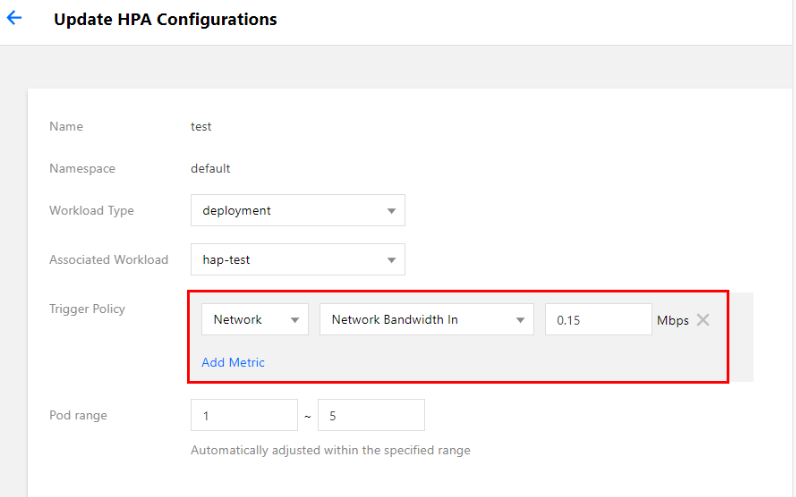
기능 확인
스케일 아웃 프로세스 시뮬레이션
구성된 HPA 기능(시뮬레이션된 클라이언트)을 테스트하기 위해 다음 명령을 실행하여 클러스터에서 임시 Pod를 시작합니다.
kubectl run -it --image alpine hpa-test --restart=Never --rm /bin/sh
임시 Pod에서 다음 명령을 실행하여 단기간에 "hpa-test" 서비스에 액세스하는 많은 수의 요청으로 인해 이그레스 트래픽 대역폭이 증가하는 상황을 시뮬레이션합니다.
# hpa-test.default.svc.cluster.local 은 클러스터에 있는 서비스의 도메인 이름입니다. 스크립트를 중지하려면 Ctrl+C를 누릅니다.while true; do wget -q -O - hpa-test.default.svc.cluster.local; done
테스트 Pod에서 요청 시뮬레이션 명령을 실행한 후 워크로드의 모니터링되는 Pod 수를 관찰합니다. 워크로드의 복제본 수가 16:21에 2개로 증가하는 것을 볼 수 있습니다. 이는 아래 이미지와 같이 HPA 스케일 아웃 이벤트가 트리거되었음을 나타냅니다. (본문의 스크린샷 정보는 콘솔의 실제 인터페이스보다 뒤쳐질 수 있습니다. 실제 콘솔을 기준으로 하십시오):
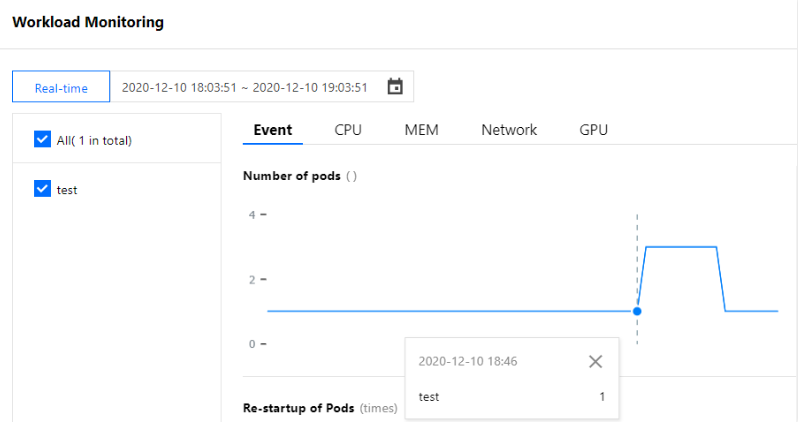
그러면 워크로드의 네트워크 이그레스 대역폭 모니터링을 통해 16:21에 네트워크 이그레스 대역폭이 약 196Kbps로 증가하여 HPA에서 설정한 네트워크 이그레스 대역폭의 목표 값을 초과하는 것을 확인할 수 있습니다. 이는 설정된 목표 값을 충족하기 위해 복제본을 추가하기 위해 HPA 스케일링 알고리즘이 트리거되었음을 나타냅니다. 따라서 아래 이미지와 같이 워크로드의 복제본 수가 2로 변경되었습니다. (본문의 스크린샷 정보는 콘솔의 실제 인터페이스보다 뒤쳐질 수 있습니다. 실제 콘솔을 기준으로 하십시오):
주의사항
HPA 스케일링 알고리즘은 수식 계산에 의존하여 스케일링 로직을 제어하는 것이 아니라 스케일 아웃/인이 필요한지 여부를 결정하기 위해 여러 차원을 고려합니다. 따라서 실제 구현은 예상과 약간 다를 수 있습니다. 자세한 내용은 알고리즘 세부 정보를 참고하십시오.
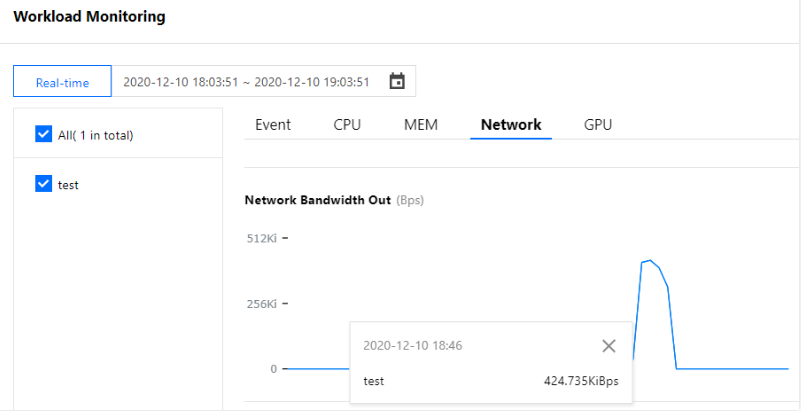
스케일 인 프로세스 시뮬레이션
스케일 인 프로세스를 시뮬레이션할 때 요청 시뮬레이션 명령 실행을 약 16:24에 수동으로 중지합니다. 모니터링을 통해 네트워크 이그레스 대역폭이 스케일 아웃 전 수준으로 감소하는 것을 관찰할 수 있습니다. 이 때 HPA 로직에 따라 아래 이미지와 같이 워크로드 스케일 인을 위한 조건이 충족됩니다. (이 글의 스크린샷 정보는 콘솔의 실제 인터페이스보다 뒤쳐질 수 있습니다. 실제 콘솔을 기준으로 하십시오):
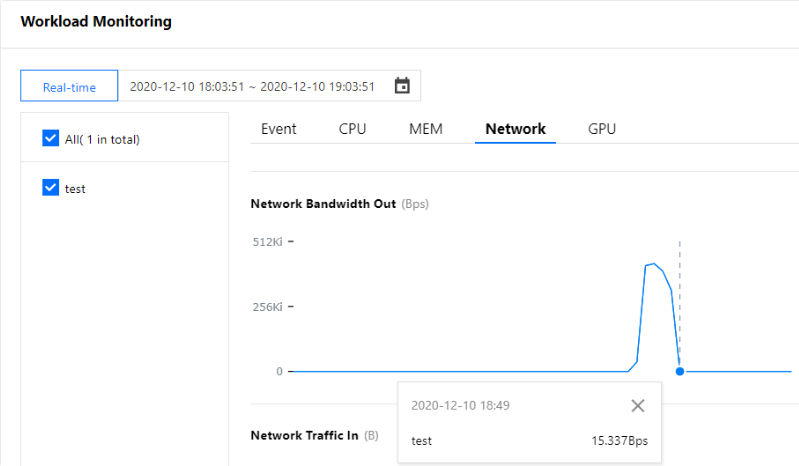
그러나 아래 이미지에 표시된 워크로드 Pod 수 모니터링에 따르면 워크로드는 16:30까지 HPA 스케일 인을 트리거하지 않았습니다. 이는 HPA가 트리거된 후 짧은 시간 내에 메트릭 변동으로 인한 빈번한 조정 작업을 방지하기 위해 기본 5분 허용 시간 알고리즘이 있기 때문입니다. 자세한 내용은 쿨링/딜레이 지원을 참고하십시오. 아래 이미지와 같이 명령이 중지된 지 5분이 지나면 HPA 스케일링 알고리즘에 따라 워크로드 복제본의 수가 초기 설정인 복제본 1개로 다시 줄어듭니다. (이 글의 스크린샷 정보는 콘솔의 실제 인터페이스보다 뒤쳐질 수 있습니다. 실제 콘솔을 기준으로 하십시오):
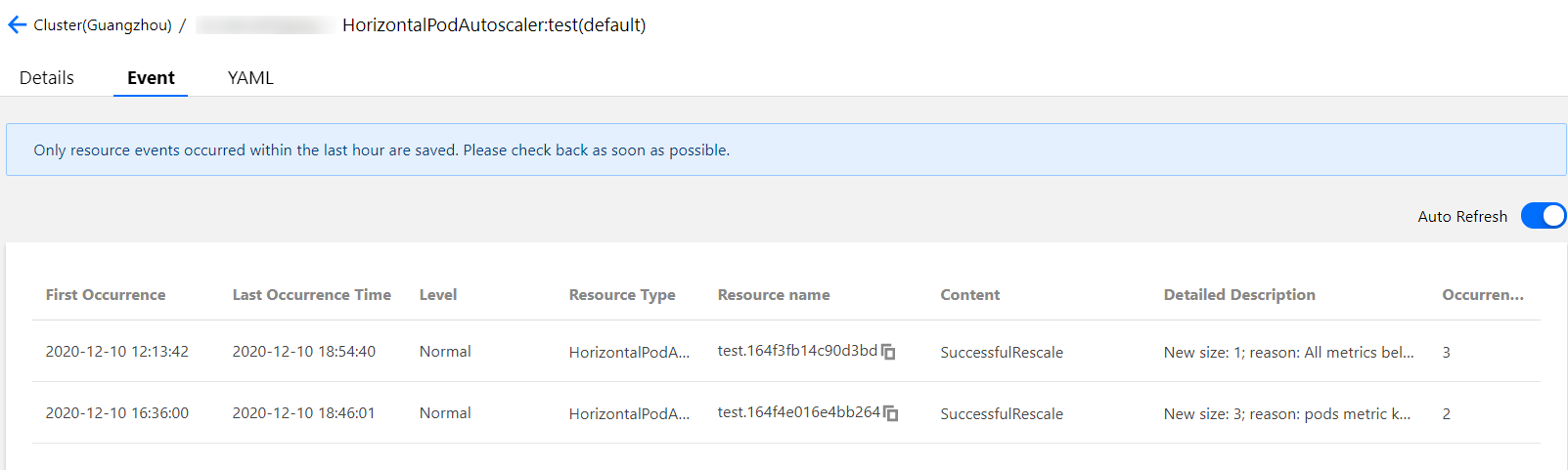
TKE에서 HPA 스케일링 이벤트가 발생하면 해당 HPA 인스턴스의 이벤트 목록에 해당 이벤트가 표시됩니다. 이벤트 알림 목록의 시간에는 ‘최초 발생 시간’과 ‘마지막 발생 시간’이 포함됩니다. ‘최초 발생 시간’은 동일한 이벤트가 처음 발생한 시간을 나타내고 ‘마지막 발생 시간’은 동일한 이벤트가 발생한 가장 최근 시간을 나타냅니다. 따라서 아래 그림의 이벤트 목록에서 볼 수 있듯이 ‘마지막 발생 시간’ 필드는 이 예제의 스케일 아웃 이벤트에 대해 16:21:03, 스케일 인 이벤트에 대해 16.29:42을 표시합니다. 여기에 표시되는 시점은 워크로드 모니터링의 시점과 일치합니다.
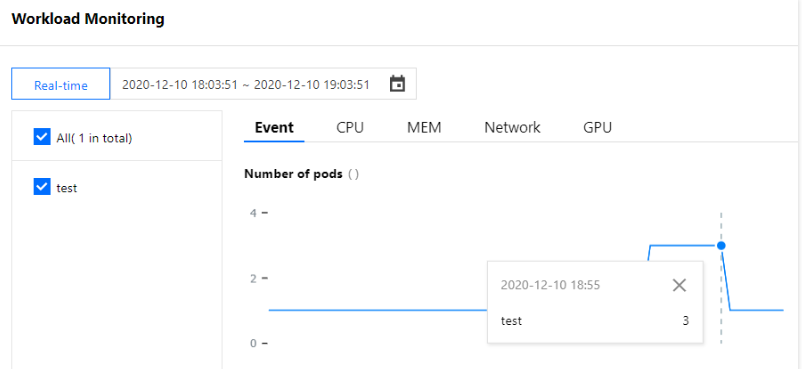
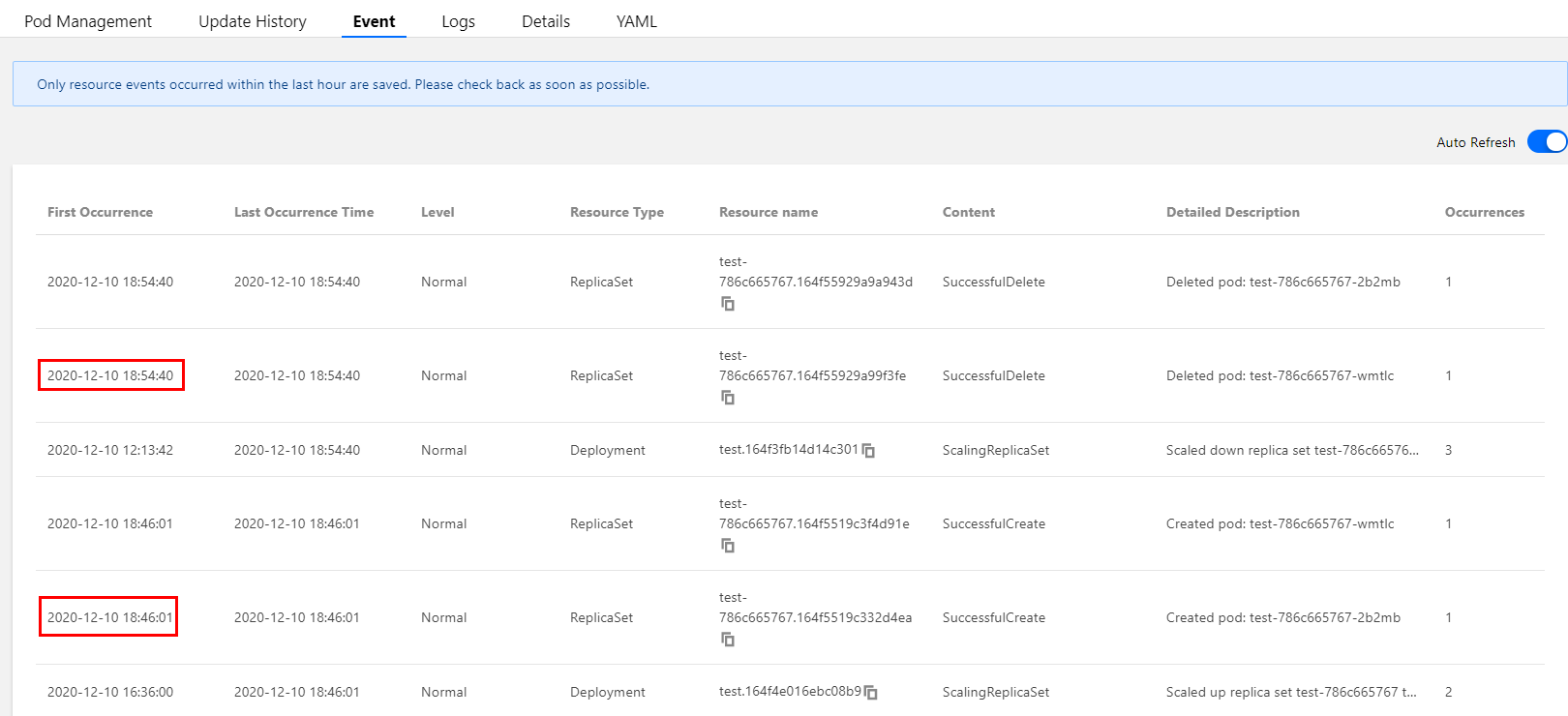
또한 워크로드 이벤트 목록에는 HPA 발생 시 워크로드별 복제본 추가/삭제 이벤트도 기록됩니다. 아래 이미지와 같이 워크로드 스케일 인/아웃 시점이 HPA 이벤트 목록에 표시되는 시점과 일치합니다. 복제본 수가 증가한 시점은 16:21:03이고, 복제본 수가 감소한 시점은 16:29:42입니다.
요약
이 예시는 TKE의 HPA 기능을 보여주고 워크로드 HPA 조정을 트리거하기 위한 지표로 TKE 사용자 정의 지표 유형 네트워크 이그레스 대역폭을 사용하는 방법을 보여줍니다.
워크로드의 실제 메트릭 값이 HPA에서 설정한 목표 메트릭 값을 초과하면 HPA는 스케일 아웃 알고리즘에 따라 적절한 복제본 수를 계산하고 스케일 아웃을 구현합니다. 이렇게 하면 워크로드의 메트릭 수준이 기대치를 충족하고 워크로드가 건강하고 안정적인 방식으로 실행될 수 있습니다.
워크로드의 실제 메트릭 값이 HPA에서 구성한 대상 메트릭 값보다 훨씬 낮을 경우 HPA는 허용 시간이 만료될 때까지 기다린 후 적절한 복제본 수를 계산하여 스케일 인을 구현하고 유휴 리소스를 릴리스합니다. 이렇게 하면 리소스 활용도가 향상됩니다. 또한 프로세스 전반에 걸쳐 관련 이벤트가 HPA 및 워크로드 이벤트 목록에 기록되므로 전체 워크로드 스케일링 프로세스를 추적할 수 있습니다.
피드백