プロダクト概要
製品の強み
適用シーン
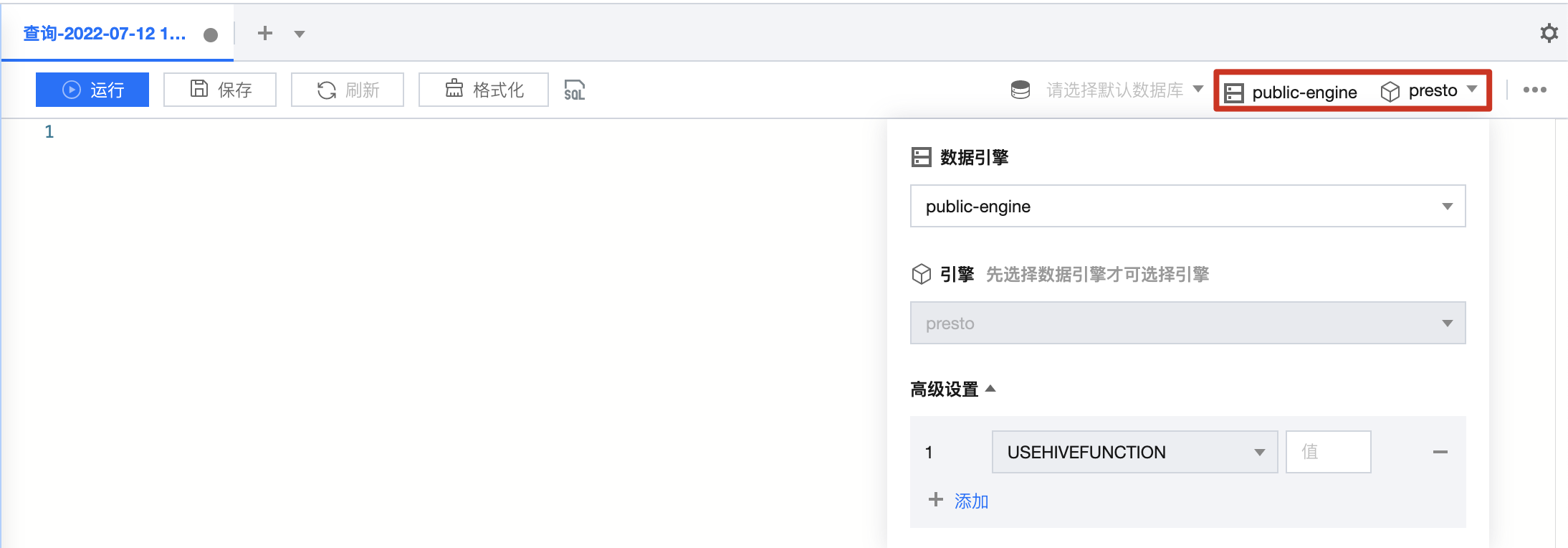
SELECT/*+OPTIONS('useHiveFunction'='false')*/prestofunc(xx)
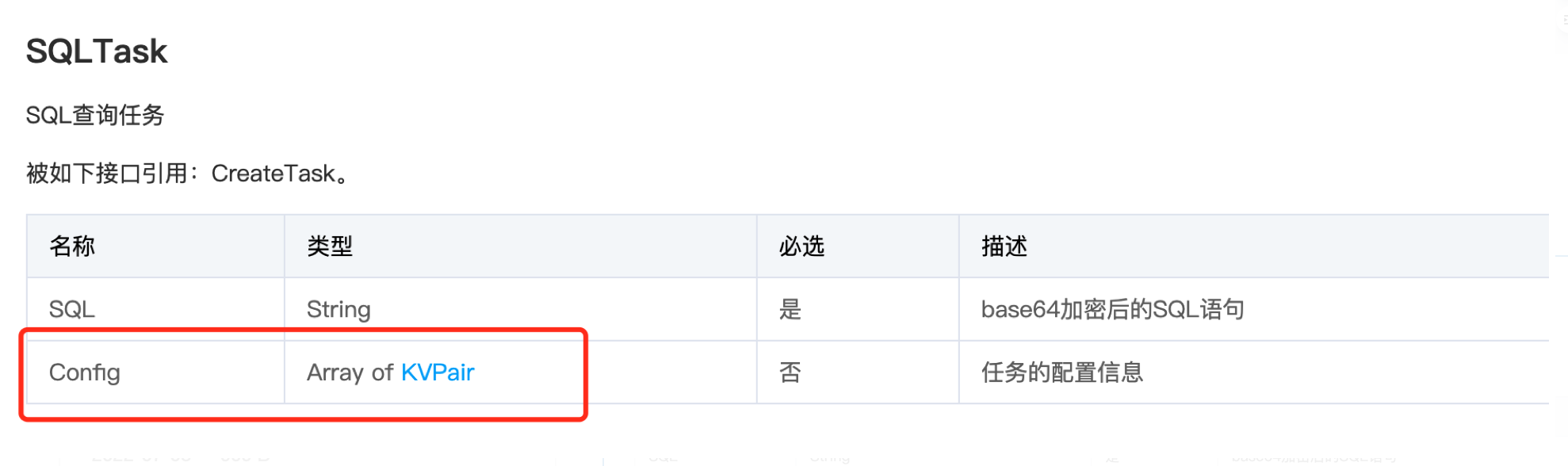
Stringstatement="SELECTdate_add('week',3,TIMESTAMP'2001-08-2203:04:05.321')";TasksInfotask=newTasksInfo();task.setTaskType("SQLTask");task.setSQL(Base64.getEncoder().encodeToString(statement.getBytes()));//以下のパラメータ設定を追加KVPairpair=newKVPair();pair.setKey("useHiveFunction");pair.setValue("false");task.setConfig(newKVPair[]{pair});CreateTasksRequestrequest=newCreateTasksRequest();request.setDatabaseName("");request.setDataEngineName(PRESTO_ENGINE);request.setTasks(task);
&presto.USEHIVEFUNCTION=true パラメータまたは info.setProperty("presto.USEHIVEFUNCTION","false"); を追加します。Connectionconnection=DriverManager.getConnection("jdbc:dlc:dlc.tencentcloudapi.com?task_type=SQLTask&x省略中间参数xx&presto.USEHIVEFUNCTION=true",info);またはinfo.setProperty("presto.USEHIVEFUNCTION","false");info.setPropertv("user","");info.setProperty("password","");
関数名 | 戻り値 | 関数機能説明 |
abs(x) | x と一致 | x の絶対値を返します |
cbrt(x) | double | x の立方根を返します |
ceil(x) | ceiling(x) | x と一致 | x の最も近い整数を返します。例えば:ceil(2.2); -->3 |
cosine_similarity(x, y) | double | ベクトル x と y の類似度を返します 例えば:SELECT cosine_similarity(MAP(ARRAY['a'], ARRAY[1.0]), MAP(ARRAY['a'], ARRAY[2.0])); -->1.0 |
degrees(x) | double | ラジアンを角度に変換します |
e() | double | 定数 e を返します |
exp(x) | double | x の e 乗を返します |
floor(x) | x と一致 | x の最も近い整数を返します。例えば:floor(2.2); -->2 |
ln(x) | double | x の自然対数を返します |
log2(x) | double | x の2を底とする対数を返します |
log10(x) | double | x の10を底とする対数を返します |
mod(n, m) | n と一致 | n を m で割った余りを返します |
pi() | double | 定数Piを返します |
pow(x, p) | power(x, p) | double | x の p 乗を返します |
radians(x) | double | 角度xをラジアンに変換します |
rand() | random() | double | 0.0 <= x < 1.0 の範囲内のランダムな値を返します。 |
random(n) | n と一致 | 0 から n (nを含まない) までの間のランダムな数を返します |
secure_rand() | secure_random() | double | 0.0 <= x < 1.0 の範囲内の暗号化されたランダムな値を返します。 |
secure_random(lower, upper) | lower と一致 | lower <= x < upper の範囲内の暗号化されたランダムな値を返します(ただし、lower < upper) |
round(x) | x と一致 | x を最も近い整数に丸めて返します |
round(x, d) | x と一致 | x を小数点以下 d 桁に丸めて返します |
sign(x) | x と一致 | x に対応する符号を返します。x > 0 の場合は 1、x < 0 の場合は -1、x = 0 の場合は 0 を返します。 |
sqrt(x) | double | x の平方根を返します |
truncate(x) | bigint | 小数点以下を切り捨てた数を返します 例えば:truncate(4.9) -->4 |
truncate(x, n) | double | x の小数点以下n桁を切り捨てて返します。n<0の場合は、小数点の左側から切り捨てます。 例えば:truncate(12.333, -1) -->10.0;truncate(12.333,0) -->12.0;truncate(12.333,1) -->12.3 |
関数名 | 戻り値 | 関数機能説明 |
length(b) | bigint | バイト単位で、bのバイナリ長を返します |
concat(b1, ..., bN) | varbinary | b1,…,bNを連結したバイナリ値を返します |
substr(b, start) | varbinary | b の start 位からバイナリ値を切り取り、start > 0 の場合は先頭から、start < 0 の場合は末尾から切り取ります |
substr(b, start, length) | varbinary | b の start 位から length の長さのバイナリ値を切り取り、start > 0 の場合は先頭から、start < 0 の場合は末尾から切り取ります |
to_base64(b) | varchar | バイナリデータ b を base64 文字列に変換します |
from_base64(string) | varbinary | base64エンコードされた文字列をバイナリデータに変換します |
to_base64url(b) | varchar | URLセーフな文字を使用して、バイナリデータ b を base64 文字列に変換します |
from_base64url(string) | varbinary | URLセーフな文字を使用して、base64エンコードされた文字列をバイナリデータに変換します |
from_base32(string) | varbinary | base32でエンコードされた文字列をバイナリデータに変換する |
to_base32(b) | varchar | バイナリデータ b を base32 文字列に変換する |
to_hex(b) | varchar | バイナリデータ b を16進数文字列に変換する |
from_hex(string) | varbinary | 16進数エンコードされた文字列をバイナリデータに変換する |
lpad(b, size, padb) | varbinary | b の左側に padb を連結し、長さが size に達するまで繰り返したバイナリ数を返す |
rpad(b, size, padb) | varbinary | b の右側に padb を連結し、長さが size に達するまで繰り返したバイナリ数を返す |
crc32(b) | bigint | CRC32アルゴリズムを使用して式の巡回冗長検査値を計算する |
md5(b) | varbinary | バイナリbのmd5値を計算する |
sha1(b) | varbinary | バイナリbのsha1値を計算する |
sha256(b) | varbinary | バイナリbのsha256値を計算する |
sha512(b) | varbinary | バイナリbのsha512値を計算する |
xxhash64(b) | varbinary | バイナリbのxxhash64値を計算する |
関数名 | 戻り値 | 関数機能説明 |
bit_count(x, bits) | bigint | x における bit のビット数を返します |
bitwise_and(x, y) | bigint | x と y の AND を返します |
bitwise_not(x) | bigint | x のビット単位の NOT を返します |
bitwise_or(x, y) | bigint | x と y の OR を返します |
bitwise_xor(x, y) | bigint | x と y の XOR を返します |
bitwise_left_shift(value, shift) | 入力と一致 | value の左シフト shift ビットの値を返します bitwise_left_shift(TINYINT '7', 2) --> 28 |
bitwise_right_shift(value, shift) | 入力と一致 | value の右シフト shift ビットの値を返します bitwise_right_shift(TINYINT '7', 2) -->1 |
関数名 | 戻り値 | 関数機能説明 |
chr(n) | varchar | n の Unicode 文字を返す |
codepoint(string) | integer | 文字列のUnicode値を返す 例えば:codepoint('0') -->48 |
concat(string1, ..., stringN) | varchar | string1,….,stringNの連結文字列を返す |
length(string) | bigint | 文字列の長さを返す |
hamming_distance(string1, string2) | bigint | 2つの(同じ長さの)文字列の対応する位置にある異なる文字の数を返します 例えば:hamming_distance(abc, art) -->2 |
levenshtein_distance(string1, string2) | bigint | 2つの文字列間で、一方から他方に変換するために必要な最小の編集(挿入、削除、置換)回数を返します 例えば:levenshtein_distance('ab', 'abcde') -->3 |
lower(string) | varchar | stringを小文字に変換した文字列を返す |
upper(string) | varchar | stringを大文字に変換した文字列を返す |
ltrim(string) | varchar | 文字列の左側のスペースを削除 |
rtrim(string) | varchar | 文字列の後ろのスペースを削除 |
trim(string) | varchar | 文字列からスペースを削除して返す |
replace(string, search) | varchar | 文字列からすべてのsearch文字を削除する |
replace(string, search, replace) | varchar | search文字列をreplace文字列に置き換える replace('abcavc', 'a', 'c') --> 'cbccvc' |
reverse(string) | varchar | 文字列を逆順に並べ替えて返す 例えば:reverse('abc') --> 'cba' |
lpad(string, size, padstring) | varchar | stringの左側にpadstringを連結し、文字列の長さがsizeに達するまで繰り返します。sizeがstringより小さい場合、stringを長さsizeの文字列に切り詰めます。 |
rpad(string, size, padstring) | varchar | stringの右側にpadstringを連結し、文字列の長さがsizeに達するまで繰り返します。sizeがstringより小さい場合、stringを長さsizeの文字列に切り詰めます。 |
split(string, delimiter) | array | delimiterで分割された文字列の配列を返します |
split(string, delimiter, limit) | array | delimiterで分割された文字列をlimitのサイズ制限に従って配列にし、limit > 0の場合、配列の最後の要素には文字列の残りの内容がすべて含まれます 例えば:select split('ab-cd-efg', '-', 2) -->['ab','cd-efg'] |
split_part(string, delimiter, index) | varchar | delimiter で分割された文字列の配列において、index 位置の文字列を返します。フィールドインデックスは1から始まります。index > 配列の長さの場合、null を返します。 例えば:select split_part('ab-cd-efg', '-', 2) -->'cd' |
split_to_map(string, entryDelimiter, keyValueDelimiter) | map<varchar, varchar> | entryDelimiter と keyValueDelimiter で文字列を分割した後のmapを返します 例えば:select split_to_map('a:1,b:2', ',', ':') -->{'a':'1','b':'2'} |
split_to_map(string, entryDelimiter, keyValueDelimiter, function(K, V1, V2, R)) | map<varchar, varchar> | entryDelimiter と keyValueDelimiter で文字列を分割した後のmapを返します。重複するkeyがある場合、functionで指定されたルールに従ってkeyに対応するvalueを返します 例えば:split_to_map('a:1,b:2;a:3',‘,' , ':’, (k, v1, v2) -> v1)-->{'a':'1','b':'2'} |
substr(string, start) | varchar | 文字列 string の start 位置以降の文字列を返します。位置は1から始まり、start <0の場合は文字列の末尾からカウントします |
substr(string, start, length) | varchar | 文字列 string の start 位置から length の長さの文字列を返します。位置は1から始まり、start <0の場合は文字列の末尾からカウントします |
position(substring IN string) | bigint | string内でsubstringが最初に現れる位置を返します。位置は1から始まります。見つからない場合は0を返します。 |
strpos(string, substring) | bigint | string内でsubstringが左から右へ最初に現れる位置を返します。位置は1から始まります。見つからない場合は0を返します。 strpos('abcdefg', 'a') -->1 |
strpos(string, substring, instance) | bigint | string内でsubstringが左から右へinstance回目に現れる位置を返します。instance >0、位置は1から始まります。見つからない場合は0を返します。 例えば:strpos('abcaefg', 'ab',2) -->0 |
strrpos(string, substring) | bigint | string内でsubstringが右から左へ最初に現れる位置を返します。位置は1から始まります。見つからない場合は0を返します。 例えば:strpos('abcdefg', 'a') -->7 |
strrpos(string, substring, instance) | bigint | string内でsubstringが右から左へinstance回目に現れる位置を返します。instance >0、位置は1から始まります。見つからない場合は0を返します。 例えば:strpos('abcaefg', 'a',2) -->0 |
to_utf8(string) | varbinary | 文字列をutf8エンコードされたバイナリ数に変換する |
from_utf8(binary) | varchar | バイナリ数をutf8エンコードされた文字列に変換し、無効な文字はUnicode文字U+FFFDで置き換えます |
from_utf8(binary, replace) | varchar | バイナリ数をutf8エンコードされた文字列に変換し、無効な文字はreplaceで置き換えます |
関数名 | 戻り値 | 関数機能説明 |
current_date | date | 現在の日付を返す |
current_time | time | 現在のタイムゾーン付きの時間を返す |
current_timestamp | timestamp | 現在のタイムゾーン付きのタイムスタンプを返す |
current_timezone() | varchar | 現在のタイムゾーンを返す |
date(x) | date | 現在の日付を返す |
last_day_of_month(x) | date | 今月の最終日を返す |
from_unixtime(unixtime) | timestamp | unixタイムスタンプを返す from_unixtime(1475996660) -->2016-10-09 15:04:20.000 |
to_unixtime(timestamp) | double | timestampのunixタイムスタンプを返す |
from_unixtime(unixtime, string) | timestamp | unixtimeのタイムスタンプを返し、stringでタイムゾーンを指定します from_unixtime(1617256617,'Asia/Shanghai') -->2021-04-01 13:56:57.000 Asia/Shanghai |
from_iso8601_timestamp(string) | timestamp | iso8601形式で文字列をタイムスタンプに変換する |
from_iso8601_date(string) | date | iso8601 形式で string を日付に変換します |
localtime | time | 現在の時刻を返す |
localtimestamp | timestamp | 現在のタイムスタンプを返す |
now() | timestamp | 現在のタイムゾーン付きのタイムスタンプを返す |
to_iso8601(x) | varchar | xのiso8601形式の文字列を返します。xは日付、タイムスタンプ、またはタイムゾーン付きのタイムスタンプを指定できます |
date_trunc(unit, x) | 入力と一致 | xの時間をunit単位で切り捨てます。unitはsecond、minute、hour、day、week、month、quarter、yearを指定できます。 date_trunc('hour', TIMESTAMP '2020-03-17 02:09:30') --> '2020-03-17 02:00:00' |
date_add(unit, value, timestamp) | 入力と一致 | 対応する単位の間隔時間を加減算して新しいタイムスタンプを算出します。value >0 は加算、value < 0 は減算を表します。 unit は millisecond、second、minute、hour、day、week、month、quarter、year です。 例えば:date_add('hour', 2, cast ('2023-07-20 20:22:22.022' as timestamp) -->'2023-07-20 22:22:22.022' |
date_diff(unit, timestamp1, timestamp2) | bigint | 指定された単位(ミリ秒、秒、分、時、日、週、月、四半期、年)で2つのタイムスタンプの時間差を返します。 例えば:date_diff('hour', cast ('2023-07-01 22:22:22' as timestamp) , cast ('2023-07-03 22:22:22' as timestamp) -->48 |
extract(field FROM x) | bigint | fieldからxの時間を抽出して返します。fieldには次の値を指定できます:year、quarter、month、week、day、dow、doy、yow、hour、minute、second、timezone_hour、timezone_minute、day_of_week、day_of_year、day_of_month 例えば:extract(year from current_date) 2023 |
day(x) | bigint | x が月の何日目であるかを返します |
day_of_month(x) | bigint | x が月の何日目であるかを返します |
day_of_week(x) | bigint | x が週の何日目であるかを返します(範囲は1~7) |
day_of_year(x) | bigint | x が年の何日目であるかを返します |
dow(x) | bigint | x が週の何日目であるかを返します。day_of_week(x)と同じです |
doy(x) | bigint | x が年の何日目であるかを返します。day_of_year(x)と同じです |
hour(x) | bigint | x が一日の何時目かを返します。範囲は0~23です |
millisecond(x) | bigint | x が一秒の何ミリ秒目かを返します |
minute(x) | bigint | x が一時間の何分目かを返します |
month(x) | bigint | x が年の何ヶ月目であるかを返します |
quarter(x) | bigint | x が年の第何四半期であるかを返します |
second(x) | bigint | x が一分の何秒目かを返します |
week(x) | bigint | x が年の何週目であるかを返します |
week_of_year(x) | bigint | x が年の何週目であるかを返します |
year(x) | bigint | x の年を返します |
関数名 | 戻り値 | 関数機能説明 |
array_distinct(x) | array | 配列から重複する値xを削除します。 |
array_intersect(x, y) | array | x と y の交差部分から重複しない要素を返します。 |
array_union(x, y) | array | x と y の和集合から重複しない要素を返します。 |
array_except(x, y) | array | x に属し、y に属さない重複しない要素を返します。(差集合) |
array_join(x, delimiter, null_replacement) | varchar | delimiterを使用してx配列の要素を接続し、null_replacementで配列内の空の値を埋めます。null_replacementはオプションの文字です。 |
array_max(x) | x | 入力配列の最大値を返す |
array_min(x) | x | 入力配列の最小値を返す |
array_position(x, element) | bigint | 配列x内で最初にelementが出現する位置(数字)を返します(見つからない場合は0を返します) |
array_remove(x, element) | array | 配列xからelementと同じすべての要素を削除します |
array_sort(x) | array | xのソート結果を返します。xの要素はソート可能でなければなりません。空の要素は返される配列の末尾に配置されます。 |
array_sort(array(T), function(T, T, int)) | array(T) | 配列を比較関数functionに基づいてソートした結果を返します 例えば:array_sort(ARRAY [3, 2, 5, 1, 2], (x, y) -> IF(x < y, 1, IF(x = y, 0, -1))) -->[5, 3, 2, 2, 1] |
arrays_overlap(x, y) | ブール値 | 配列 x と y に共通の非空要素があるかどうかを判断します |
cardinality(x) | bigint | 配列の基数(サイズ)を返します |
concat(array1、array2、…、arrayN) | array | 配列array1、array2、...、arrayNを連結します |
contains(x, element) | ブール値 | 配列 x が element を含むかどうかを判断します |
element_at(array(E)、index) | E | 配列 array の index 位置の要素を返します。index > 0 の場合は左から右に数え、index < 0 の場合は右から左に数えます。 |
filter(array(T), funciton(T, boolean)) | array(T) | 関数functionがtrueを返す要素で構成される新しい配列を返します 例えば:filter( array[5, -6, NULL, 7], x -> x > 0); --> [5, 7] |
repeat(element、count) | array | elementをcount回繰り返す |
reverse(x) | array | 配列xの逆順の配列を返します。 |
sequence(start, stop, n) | array(bigint ) | startからstopまで、ステップnで整数シーケンスを生成します。nはオプションで、指定しない場合は1です。startがstop以下の場合、毎回1ずつ増加し、それ以外の場合は-1ずつ増加します。 |
shuffle(x) | array | 配列の要素をシャッフルします |
slice(x, start, length) | array | start位置から長さlengthの配列にスライスした配列xを返します。 |
transform(array(T), function(T, U)) | array(U) | array配列の各要素Tをfunctionで処理した後に生成されるUで構成される配列を返します 例えば:transform(array [5, 6], x -> x + 1); -- [6, 7] |
関数名 | 戻り値 | 関数機能説明 |
is_json_scalar(json) | boolean | jsonがjson数値またはjson文字列またはtrueまたはfalseまたはnullであるかどうかを判断します 例えば: is_json_scalar('[1, 2, 3]') -->false |
json_array_contains(json, value) | boolean | json(json配列を含む文字列)にvalueが存在するかどうかを判断します。 例えば: json_array_contains('[1, 2, 3]', 2) -->true |
json_array_length(json) | bigint | json(json配列を含む文字列)の配列の長さを返します。 例えば: json_array_length('[1, 2, 3]') --> 3 |
json_extract(json, json_path) | json | json(JSONを含む文字列)に対してJSONPathのような式json_pathを計算し、結果をjsonとして返します。 例えば: json_extract('{"log":{"file":{"path":"/etc/nginx/logs/access.log"},"offset":19991212}}', '$.log.file.path')--> "/etc/nginx/logs/access.log" |
json_extract_scalar(json, json_path) | varchar | json_extract()と同様ですが、結果の値をJSON文字列ではなく文字列として返します。json_pathで参照される値は、ブール値、数値、または文字列でなければなりません。 例えば:json_extract_scalar('{"log":{"file":{"path":"/etc/nginx/logs/access.log"},"offset":19991212}}', '$.log.file.path') -->/etc/nginx/logs/access.log |
json_format(json) | varchar | 入力されたJSON値からシリアライズされたJSONテキストを返します。これはjson_parse()の逆関数です。 例えば:json_format(JSON '[1, 2, 3]') -->[1,2,3] |
json_parse(string) | json | 入力されたJSONテキストからデシリアライズされたJSON値を返します。これはjson_format()の逆関数です。 例えば:json_parse('[1, 2, 3]') -->[1,2,3] |
json_size(json, json_path) | bigint | json_extract()と同様ですが、戻り値のサイズを返します。オブジェクトまたは配列の場合、サイズはメンバーの数であり、スカラー値のサイズはゼロです。 例えば:json_size('{"x": [1, 2, 3]}', '$.x') -->3 |
関数名 | 戻り値 | 関数機能説明 |
arbitrary(x) | 入力と一致 | 存在する場合、xの任意の非NULL値を返します |
array_agg(x) | array[x] | 入力x要素から作成された配列を返します |
avg(x) | double | すべての入力値の平均値(算術平均)を返します |
bool_and(boolean) | every(boolean) | boolean | すべての入力値がtrueの場合、trueを返し、それ以外の場合はfalseを返します |
bool_or(boolean) | boolean | 入力された値のいずれかがtrueの場合、trueを返し、それ以外の場合はfalseを返します |
checksum(x) | varbinary | 入力された値のチェックサムを返します |
count(*) | bigint | 行数を返します |
count(x) | bigint | 空でない入力値の数を返します |
count_if(x) | bigint | 入力値の中でtrueの値の数を返します。count(CASE WHEN x THEN 1 END)と同等です |
geometric_mean(x) | double | 幾何平均値を返します |
max_by(x, y) | 入力 x と一致 | x における y の最大値に関連する値を返します |
max_by(x, y, n) | array[x] | y の降順に並べ替え、x における y の n 個の最小値に関連する n 個の値を返します |
min_by(x, y) | 入力 x と一致 | x における y の最小値に関連する値を返します |
min_by(x, y, n) | array[x] | y の昇順に並べ替え、x における y の n 個の最小値に関連する n 個の値を返します |
max(x) | 入力と一致 | 入力中の最大値を返す |
max(x, n) | 入力 x と一致 | 入力中の最大の n 個の値を返す |
min(x) | 入力と一致 | 入力中の最小値を返す |
min(x, n) | 入力 x と一致 | 入力中の最小のn個の値を返す |
set_agg(x) | 入力と一致 | 重複しない要素の配列を返す |
set_union(array(T)) | array(T) | 入力の各配列に含まれるすべての異なる値の配列を返す 例えば:select set_union(elements) FROM (VALUES ARRAY[1, 2, 3], ARRAY[2, 3, 4]) AS t(elements) -->ARRAY[1, 2, 3, 4] |
sum(x) | 入力と一致 | 返す |
bitwise_and_agg(x) | bigint | すべてのビットのANDを返す |
bitwise_or_agg(x) | bigint | すべてのビットのORを返す |
histogram(x) | | 各入力値の出現回数を含むマップを返します |
map_agg(key, value) | map(K, V) | key-valueで構成されたmapを返す |
map_union(x(K, V)) | map(K, V) | すべての入力マッピングの和集合を返します。1つのキーが複数の値に対応する場合、結果セット内のキーに対応する値は複数の値のいずれか1つになります |
map_union_sum(x(K, V)) | map(K, V) | 同じkeyを合計した後の和集合mapを返します。keyに対応するvalueが空の場合、0として計算されます |
multimap_agg(key, value) | | key-valueで構成されたmapを返します。keyは複数の値に対応できます |
関数名 | 戻り値 | 関数機能説明 |
row_number() | bigint | 各行に一意の連続番号を割り当てます |
rank() | bigint | ある値が一連の値の中で占める順位を計算します。順位が等しい場合、順位シーケンスに空きが生じます。 |
percent_rank() | double | ある値が一連の値の中で占めるパーセンテージ順位を計算します。戻り値は0から1の間の小数で表されます。 |
dense_rank() | bigint | ある値が一連の値の中で占める順位を計算します。ランクが等しい場合、関数rankとは異なり、dense_rankは順位シーケンスに空位を生じさせません。 |
cume_dist() | bigint | ある値がパーティション内のすべての値に対して占める位置を計算します。 |
ntile(n) | bigint | ウィンドウパーティションの行をn個のバケットに分割し、行が属するバケット番号を1からnの範囲で返します。 |
first_value(x) | 入力と一致 | パーティション内の列の最初のデータの値を返します |
last_value(x) | 入力と一致 | パーティション内の列の最後のデータの値を返します |
nth_value(x, n) | 入力と一致 | ウィンドウの先頭からn行目の値を返します。nは1から始まります。 ignoreNulls=trueの場合、n行目を検索する際にnullをスキップします。それ以外の場合、各行がnにカウントされます。 そのようなn番目の行が存在しない場合(例えば、nが10でウィンドウサイズが10未満の場合)、nullを返します。最初の引数は列名、2番目の引数は前のn番目の行です。 |
lead(x[, n[, default_value]]) | 入力と一致 | ウィンドウ内の現在の行から下にn行目の値を返します。nのデフォルト値は1で、defaultのデフォルト値はnullです。 n行目の値がnullの場合、nullを返します。 そのようなオフセット行が存在しない場合(例えば、オフセットが1でウィンドウの最後の行に下方向の行がない場合)、デフォルト値を返します。最初の引数は列名、2番目の引数は前のn行目、3番目の引数はデフォルト値です。 |
lag(x[, n[, default_value]]) | 入力と一致 | ウィンドウ内の現在の行から上にn行目の値を返します。nのデフォルト値は1で、defaultのデフォルト値はnullです。 n行目の値がnullの場合、nullを返します。 そのようなオフセット行が存在しない場合(例えば、オフセットが1でウィンドウの最初の行に上方向の行がない場合)、defaultを返します。最初の引数は列名、2番目の引数は前のn行、3番目の引数はデフォルト値です。 |
関数名 | 戻り値 | 関数機能説明 |
url_extract_host(url) | varchar | urlのホストを返す |
url_extract_parameter(url, name) | varchar | url 内の name の最初の値を返します。RFC 1866#section-8.2.1 に従って検索します |
url_extract_path(url) | varchar | url のパスを返します |
url_extract_port(url) | bigint | url のポートを返します |
url_extract_protocol(url) | varchar | url のプロトコルを返します |
url_extract_query(url) | varchar | url のクエリ文字列を返します |
url_encode(value) | varchar | value を encode エンコードします |
url_decode(value) | varchar | encode エンコードされたurlをデコードします |
関数名 | 戻り値 | 関数機能説明 |
uuid ( ) | uuid | ランダムに生成されたUUIDを返します |
cast(value AS type) | type | value を type 型に強制変換します |
try_cast(value AS type) | type | value を type 型に変換し、失敗した場合は null を返します |
typeof(expr) | varchar | expr の型名を返します 例えば: typeof(cos(2) + 1.5) -->double |
regexp_extract(string, pattern) | varchar | string 内で正規表現 pattern に一致する最初の部分文字列を返します 例えば:regexp_extract('1a 2b 14m', '\\d+') ->1 |
regexp_replace(string, pattern) | varchar | string から正規表現 pattern に一致する部分文字列を削除します 例えば:regexp_replace('1a 2b 14m', '\\d+[ab] ') --> '14m' |
regexp_split(string, pattern) | | 正規表現 pattern を使用して文字列を分割し、配列を返します。後続の空文字列を保持します 例えば:regexp_split('1a 2b 14m', '\\s*[a-z]+\\s*'); -- [1, 2, 14, ] |
regexp_like(string, pattern) | boolean | string に pattern に一致する文字列が含まれているかどうかを判断します |
フィードバック