Apache Superset is a web-based data browsing and visualization application. Superset on EMR supports MySQL, Hive, Presto, Impala, Kylin, Druid, and ClickHouse.
Superset Features
Supports almost all major databases such as MySQL, PostgresSQL, Oracle, SQL Server, SQLite, and Spark SQL as well as Druid.
Provides a wide variety of visual displays and allows you to create custom dashboards.
Makes data display controllable and enables customization of displayed fields, aggregated data, and data sources.
Prerequisites
1. You have created an EMR Hadoop or Druid cluster and selected the Superset service. For more information, see Creating EMR Cluster.
2. By default, Superset is installed on the master node of your cluster. Enable the security group policy for the master node and make sure that your network can access port 18088 of the master node.
Login
Enter http://${master_ip}:18088 in your browser (or go to the EMR console > Cluster Service) to open the login page of Supserset. The default username is admin, and the password is the one you set when creating the cluster.
Adding Databases
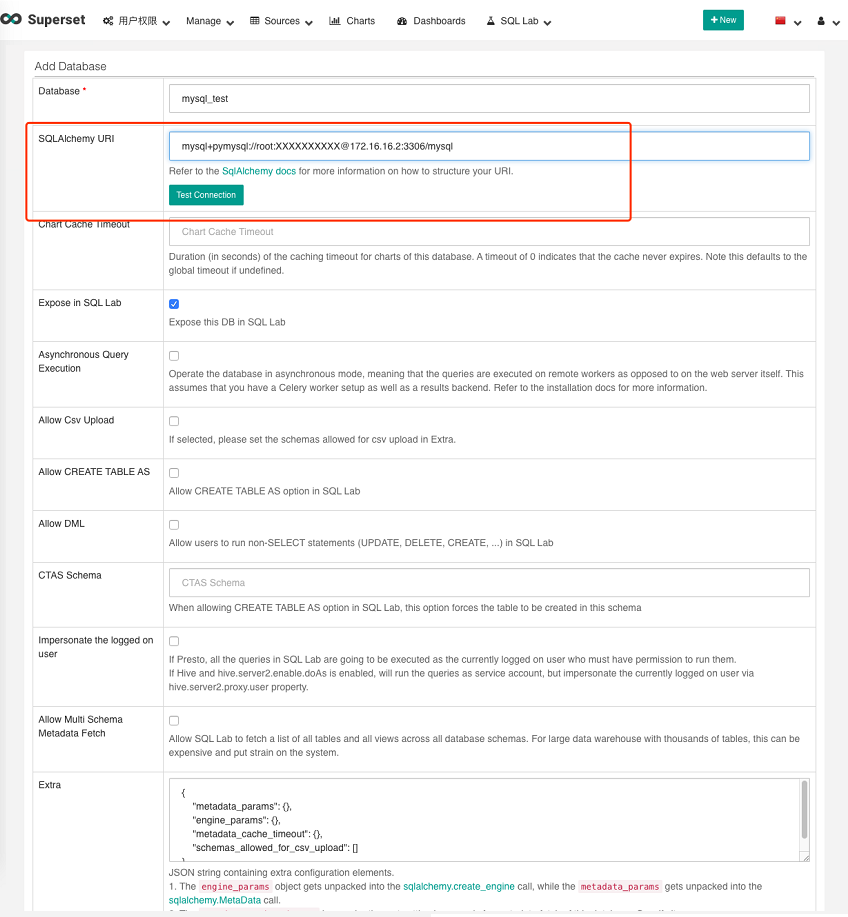
Go to Sources > Databases and click Filter List.
On the following page, add the URI of the component to be added in SQLAlchemy URI.
The SQLAlchemy URI for each database is as follows:
Name
SQLAlchemy URI
Remarks
MySQL
mysql+pymysql://:@:/
mysqlname: Username used to connect to MySQL.password: MySQL password.your_database: The MySQL database to be connected to.
Hive
hive://hadoop@<master_ip>:7001/default?auth=NONE
master_ip: Master IP of the EMR cluster.
Presto
presto://hive@:9000/hive/
Master_ip: master_ip of the EMR cluster
hive_db_name: Name of the database in Hive.
If this parameter is left empty, it will be default by default